- 第0章 请先阅读
- 第1章 起步
- 第2章 缓冲区(Buffers),窗口(Windows)和选项卡(Tabs)
- 第3章 打开和搜索文件
- 第4章 Vim 语法
- 第5章 在文件中移动
- 第6章 输入模式
- 第7章 点命令
- 第8章 寄存器
- 第9章 宏命令
- 第10章 撤销
- 第11章 可视模式
- 第12章 搜索和替换
- 第13章 全局命令
- 第14章 外部命令
- 第15章 命令行模式
- 第16章 标签
- 第17章 折叠
- 第18章 Git
- 第19章 编译
- 第20章 视图、会话和 Viminfo
- 第21章 多文件操作
- 第22章 Vimrc
- 第23章 Vim软件包
- 第24章 Vim Rumtime
第0章 请先阅读
为什么写这本教程
有很多途径可以学习Vim:vimtutor就是一个很好的途径,另外还有Vim自带的帮助手册(:help查看)包含了所有需要的参考信息。
但是在日常使用中,对于绝大部分用户的需求而言,vimtutor讲得太浅不能满足需要,而:help所提供的信息又有很多是用不上的。本指南尝试在两者之间搭一座桥,仅重点介绍关键功能,使您尽可能在最短的时间内掌握Vim中最有用的知识。
绝大部分情况下,您并不会使用到Vim100%的功能。您可能仅仅需要掌握其中20%就可以成为一名娴熟的Vim用户。本指南将为您展示Vim中最有用的功能。
本指南带有作者强烈的个人观点。它涵盖了作者在使用Vim的过程中经常用到的技巧。章节按照作者认为的,最适合初学者最符合逻辑的顺序排列。
本指南包含大量示例。当学习一个新技能时,示例是不可缺少的,大量的示例可以更有效的巩固所学概念。
部分读者可能好奇为什么要学习Vimscript?我刚使用Vim时,仅仅满足于知道如何使用Vim。随着时间推移,我越来越需要使用Vimscript去写一些自定义命令,以满足特殊的编辑需要。在您使用Vim的过程中,您早晚会接触Vimscript。所以为什么不早点学呢?Vimscript是一门小巧的脚本语言,仅需要本指南的四个章节,您就可以学到它的基础知识。
您当然可以继续使用Vim而不了解任何Vimscript知识,但了解它可以使您更加擅长Vim。
本指南同时为初学者和高级Vim用户撰写。它从宽泛而简单的概念开始讲,最后落在特殊的、进阶的技巧上。如果您已经是一名进阶用户,我还是鼓励您从头到尾阅读本指南,因为您将了解到一些新的东西。
如何从其他编辑器过渡到Vim
学习Vim的过程虽然很困难,但很具有成就感。有两种方法去学习Vim:
- 强制转换地使用Vim
- 循序渐进地使用Vim
强制转换为Vim意味着从现在开始只使用Vim,停止使用您以前使用的任何编辑器/IDE。本方法的缺点是在前一周或两周,您将面临编辑效率的严重下降。如果您是一名专职程序员,本方法可能不太行得通。这也是为什么对于大部分读者而言,我认为过渡到Vim最好是循序渐进地使用Vim。
想要循序渐进地使用Vim,应该在最开始的两个星期,每天花1个小时使用Vim作为您的编辑器,而剩下的时间您可以继续使用其他编辑器。许多现代编辑器都带有Vim插件。我刚开始时,每天花1个小时使用VSCode的Vim插件。逐渐地,我增加使用Vim插件的时间,直到最终完全使用Vim插件。记住,这些插件仅仅模拟了Vim中的一小部分功能。要想体验Vim中比如Vimscript、命令行命令(Ex模式)、以及外部集成命令的强大功能,您必须使用Vim自身。
有两个关键节点驱使我开始100%地使用Vim:一是当我理解到Vim命令的语法结构(看第4章)时。二是学会fzf.vim插件时(看第3章)。
第一个,当我了解了Vim命令的语法结构时。这是一个决定性时间节点,我终于理解了Vim用户以前讨论的是什么。我并不需要去学习上百个命令,而仅需要学习一小部分命令,然后就可以凭直觉将它们串起来去做很多事情。
第二个,fzf插件我经常使用,该插件具有类似IDE的模糊文件查找功能。当我学会在Vim中如何使用该功能时,我的编辑效率极大提升,从此再也回不去了。
尽管每一个程序都是不同的。但仔细一想,您会发现您所偏爱的编辑器/IDE总有1个或2个功能是您频繁使用的。也许是模糊查找,也许是跳转至定义,或是快速编译,但不管是什么,快速确认这些功能,然后学会如何在Vim中实现它们(一般情况下Vim都能办到)。您的编辑速度将会获得一个巨大的提高。
当您使用Vim可以达到您原来50%的效率时,就是时候完全使用Vim了。
如何阅读本指南
本指南注重实效性。为了更好地在Vim中工作,您需要锻炼您的肌肉记忆,而不是大脑理解。
想学会骑自行车,您并不需要首先阅读一本骑车教程。您需要做的是骑上一辆真正的自行车,然后在实践中探索。
您需要输入每一条本指南中提到的命令。不仅如此,您还需要不断地重复,然后尝试命令的不同联合方式。想了解您刚学到命令具有什么功能,:help命令和搜索引擎是您最好的帮手。但您的目标并不是去掌握关于一条命令的全部信息,而是能够本能地、自然地使用该命令。
我本想尽可能地使本指南的知识点呈线性化展示,但有些概念还是不得不违反顺序。比如在第1章,我就提到了替换命令(:s),这个知识点要到第12章才讲。作为补救,不管是什么概念,如果被提前讲到了,我将为它提供一个简短的说明,原谅我吧。
更多帮助
关于Vim帮助手册有一个额外的小技巧:假设您想了解关于Ctrl-p在插入模式时的功能。如果您仅仅查找:h CTRL-P,您将被导航到普通模式下关于Ctrl-P的介绍页面,这并不是您想要的信息。在这种情况下,改为查找:h i_CTRL-P。添加的i_表示插入模式。注意它属于哪个模式。
语法
大部分命令或涉及的代码片段都使用代码样式(like this)。
字符串使用双引号包括(”like this”)。
Vim命令可以使用简写。比如,:join可以简写为:j。本指南全文中,我将混合使用简写和全称。对于本指南不经常使用的命令,我将使用全称。而对于经常使用的命令,我将使用简写。我为这不一致性道歉。总之,不管什么时候当您看到一个新命令,记得使用:help查看它的简写。
Vimrc
在本指南的很多地方,我将提到vimrc选项。如果您是初学者,可以把vimrc看做一个配置文件。
Vimrc直到第21章才讲。为了保持清晰,我将在这里简要的介绍如何配置Vimrc。
假设您需要设置number选项,即显示行号(set number)。如果您还没有vimrc文件,就创建一个。它通常位于根目录,名字为.vimrc。根据您的操作系统,该位置可能不同。在macOS,我将它放在~/.vimrc。要查看您的vimrc文件应该放在哪里,查看:h vimrc。
在vimrc文件内,添加一行set number。保存(:w),然后激活这一配置(:source %)。您将会在每一行的的左侧看到行号。
另外,如果您不想永久配置一个选项,您可以在Vim命令行使用set命令,输入:set number。这种方法的缺点是设置是临时的。当您关闭Vim,该配置选项将消失。
因为我们学的是Vim而不是Vi,有一个设置您必须启用,这就是nocompatible选项。在您的vimrc文件中添加set nocompatible。如果启用compatible选项,许多Vim特有的功能将会被禁止。
一般而言,不管什么时候只要有一段内容涉及vimrc选项,只需要将该选项添加到vimrc中就好了,然后保存并激活相关选项。
未来计划,错误,问题
期待未来有更多的更新。如果您发现任何错误或有什么疑问,请随意提交。
我计划近期再发布一些更新章节,敬请关注。
更多关于Vim的技巧
要了解Vim更多的信息,请关注我的推特(需墙)。@learnvim.
感谢
感谢Bram Moleenar编写了Vim,没有Vim就不会有本指南。感谢我的妻子当我编写本指南时表现的耐心和支持。感谢所有的贡献者contributors,感谢Vim社区,还有很多其他没有提及的人们。
谢谢,您们使得这件工作更加有趣。:)
第1章 起步
在本章,您将了解从终端启动Vim的几种不同方法。我写这本教程时使用的Vim版本是8.2。如果您使用Neovim或老版本的Vim,大部分情况下方法是通用的,但注意个别命令可能无效。
安装
我不会给出在某台特定机器上安装Vim的详细指令。好消息是,大部分Unix-based电脑应该预装了Vim。如果没有,大部分发行版也应该有关于如何安装Vim的指令。
从Vim的官方网站或官方仓库可以获得下载链接:
Vim命令
当您安装好Vim后,在终端运行以下命令:
vim
您应该会看到一个介绍界面。这就是您用来处理文本的工作区。不像其它大部分文本编辑器和IDE,Vim是一个模式编辑器。如果您想输入”hello”,您需要使用’i’命令切换到插入模式。按下’ihello
退出Vim
有好几种不同的方法都可以退出Vim。(译者注:在stackflow论坛上,有个著名的问题“如何退出Vim”,五年来,有超过100万开发者遇到相同的问题。^_^,这件事已经成为了开发者中的一个梗)。最常用的退出方法是在Vim中输入:
:quit
您可以使用简写:q。这是一个命令行模式的命令(command-line mode:Vim的另一种模式)。如果您在普通模式输入:,光标将移动到屏幕底部,在这里您可以输入命令。在后面的第15章,您会学到关于命令行模式更多信息。如果您处于插入模式,按下:将会在屏幕上直接显示”:”(冒号)。因此,您需要按下<Esc>键切换回普通模式。顺带说一下,在命令行模式也可以通过按<Esc>键切换回普通模式。您将会注意到,在Vim的好几种模式下都可以通过按<Esc>键切回普通模式。
保存文件
若要保存您的修改,在Vim中输入:
:write
您也可以输入简写’:w’。如果这是一个新建的文件,您必须给出文件名才能保存。下面的命令使文件保存为名为’file.txt’的文件,在Vim命令行运行:
:w file.txt
如果想保存并退出,可以将’:w’和’:q’命令联起来,在Vim命令行中输入:
:wq
如果想不保存修改而强制退出,可以在’:q’命令后加’!’(叹号),在Vim命令行中:
:q!
帮助
在本指南全文中,我将向您提及好几种Vim的帮助页面。您可以通过输入:help {命令}(:h是简写)进入相关命令的帮助文档。可以向:h命令传递主题、命令名作为参数。比如,如果想查询退出Vim的方法,在vim中输入:
:h write-quit
我是怎么知道应该搜索”write-quit”这个关键词的呢?实际上我也不知道,我仅仅只是输入’:h quit’,然后按<Tab>。Vim会自动显示相关联的关键词供用户选择。如果您需要查询一些信息,只需要输入:h后接关键词,然后按<Tab>。
打开文件
如果想在终端中使用Vim打开名为(‘hello1.txt’),在终端中运行:
vim hello1.txt
可以一次打开多个文件,在终端中:
vim hello1.txt hello2.txt hello3.txt
Vim会在不同的buffers中打开’hello1.txt’,’hello2.txt’,’hello3.txt’。在下一章您将学到关于buffers的知识。
参数
您可以在终端中向vim命令传递参数。
如果想查看Vim的当前版本,在终端中运行:
vim --version
终端中将显示您当前Vim的版本和所有支持的特性,’+’表示支持的特性,’-‘表示不支持的特性。本教程中的一些操作需要您的Vim支持特定的特性。比如,在后面的章节中提到可以使用:history查看Vim的命令行历史记录。您的Vim必须包含+cmdline_history这一特性,这条命令才能正常使用。一般情况下,如果您通过主流的安装源下载Vim的话,您安装的Vim是支持所有特性的,
您在终端里做的很多事情都可以在Vim内部实现。比如,在Vim程序中也可以查看当前Vim版本,您可以运行下面的命令,在Vim中输入:
:version
如果您想打开hello.txt文件后迅速执行一条命令,您可以向vim传递一个+{cmd}选项。
在Vim中,您可以使用:s命令(substitue的缩写)替换文本。如果您想打开hello.txt后立即将所有的”pancake”替换成”bagel”,在终端中:
vim +%s/pancake/bagel/g hello.txt
该命令可以被叠加,在终端中:
vim +%s/pancake/bagel/g +%s/bagel/egg/g +%s/egg/donut/g hello.txt
Vim会将所有”pancake” 实例替换为”bagel”,然后将所有”bagel”替换为”egg”,然后将所有”egg”替换为”donut”(在后面的章节中您将学到如何替换)。
您同样可以使用c标志来代替+语法,在终端中:
vim -c %s/pancake/bagel/g hello.txt
vim -c %s/pancake/bagel/g -c %s/bagel/egg/g -c %s/egg/donut/g hello.txt
打开多个窗口
您可以使用o和O选项使Vim打开后分别显示为水平或垂直分割的窗口。
若想将Vim打开为2个水平分割的窗口,在终端中运行:
vim -o2
若想将Vim打开为5个水平分割的窗口,在终端中运行:
vim -o5
若想将Vim打开为5个水平分割的窗口,并使前两个窗口显示hello1.txt和hello2.txt的内容,在终端中运行:
vim -o5 hello1.txt hello2.txt
若想将Vim打开为2个垂直分割的窗口、5个垂直分割的窗口、5个垂直分割窗口并显示2个文件,在终端中分别运行以下命令:
vim -O2
vim -O5
vim -O5 hello1.txt hello2.txt
挂起
如果您编辑时想将Vim挂起,您可以按下Ctrl-z。同样,您也可以使用:stop或:suspend命令达到相同的效果。若想从挂起状态返回,在终端中运行fg命令。
聪明的启动Vim
您可以向vim命令传递不同的选项(option)和标志(flag),就像其他终端命令一样。其中一个选项是命令行命令(+{cmd}或-c cmd)。当您读完本教程学到更多命令后,看看您是否能将相应命令应用到Vim的启动中。同样,作为一个终端命令,您可以将vim命令和其他终端命令联合起来。比如,您可以将ls命令的输出重定向到Vim中编辑,命令是ls -l | vim -。
若要了解更多Vim终端命令,查看man vim。若要了解更多关于Vim编辑器的知识,继续阅读本教程,多使用:help命令。
第2章 缓冲区(Buffers),窗口(Windows)和选项卡(Tabs)
(译者注:在Vim中,Buffers缓冲区,Windows窗口,Tabs选项卡是专有名词。为适应不同读者的翻译习惯,确保没有歧义,本文将不对Buffers、Windows、Tabs这三个词进行翻译)。
如果您使用过现代文本编辑器,您很可能对Windows和tabs这两个概念是非常熟悉的。但Vim使用了三个关于显示方面的抽象概念:buffers, windows, 还有tabs。在本章,我将向您解释什么是buffers, windows和tabs,以及它们在Vim中如何工作。
在开始之前,确保您的vimrc文件中开启了set hidden选项。若没有配置该选项,当您想切换buffer且当前buffer没有保存时,Vim将提示您保存文件(如果您想快速切换,您不会想要这个提示)。我目前还没有讲vimrc,如果您没有vimrc配置文件,那就创建一个。它通常位于根目录下,名字叫.vimrc。我的vimrc位于~/.vimrc。要查看您自己的vimrc文件应该放置在哪,可以在Vim命令模式中输入:h vimrc。在vimrc文件中,添加:
set hidden
保存好vimrc文件,然后激活它(在vimrc文件中运行:source %)。
Buffers
buffer到底是什么?
buffer就是内存中的一块空间,您可以在这里写入或编辑文本。当您在Vim中打开一个文件时,文件的数据就与一个buffer绑定。当您在Vim中打开3个文件,您就有3个buffers。
创建两个可使用的空文件,分别名为file1.js和file2.js(如果可能,尽量使用Vim来创建)。在终端中运行下面的命令:
vim file1.js
这时您看到的是file1.js的 buffer 。每当您打开一个新文件,Vim总是会创建一个新的buffer。
退出Vim。这一次,打开两个新文件:
vim file1.js file2.js
Vim当前显示的是file1.js的buffer,但它实际上创建了两个buffers:file1.jsbuffer和file2.jsbuffer。运行:buffers命令可以查看所有的buffers(另外,您也可以使用:ls和:files命令)。您应该会 同时 看到列出来的file1.js和file2.js。运行vim file1 file2 file3 ... filen创建n个buffers。每一次您打开一个新文件,Vim就为这个文件创建一个新的buffer。
要遍历所有buffers,有以下几种方法:
:bnext切换至下一个buffer(:bprevious切换至前一个buffer)。:buffer+ 文件名。(按下<Tab>键Vim会自动补全文件名)。:buffer+n, n是buffer的编号。比如,输入:buffer 2将使您切换到buffer #2。- 按下
Ctrl-O将跳转至跳转列表中旧的位置,对应的,按下Ctrl-I将跳转至跳转列表中新的位置。这并不是属于buffer的特有方法,但它可以用来在不同的buffers中跳转。我将在第5章详细讲述关于跳转的知识。 - 按下
Ctrl-^跳转至先前编辑过的buffer。
一旦Vim创建了一个buffer,它将保留在您的buffers列表中。若想删除它,您可以输入:bdelete。这条命令也可以接收一个buffer编号(:bdlete 3将删除buffer #3)或一个文件名(:bdelete然后按<Tab>自动补全文件名)。
我学习buffer时最困难的事情就是理解buffer如何工作,因为我当时的思维已经习惯了使用主流文本编辑器时关于窗口的概念。要理解buffer,可以打个很好的比方,就是打牌的桌面。如果您有2个buffers,就像您有一叠牌(2张)。您只能看见顶部的牌,虽然您知道在它下面还有其他的牌。如果您看见file1.jsbuffer,那么file1.js就是顶部的牌。虽然您看不到其他的牌file2.js,但它实际上就在那。如果您切换buffers到file2.js,那么file2.js这张牌就换到了顶部,而file1.js就换到了底部。
如果您以前没有用过Vim,这是一个新的概念。花上几分钟理解一下。
退出Vim
顺带说一句,如果您已经打开了多个buffers,您可以使用quit -all来关闭所有的buffers:
:qall
如果您想关闭所有buffers但不保存,仅需要在后面加!(叹号)就行了:
:qall!
若要保存所有buffers然后退出,请运行:
:wqall
Windows
一个window就是在buffer上的一个视口。如果您使用过主流的编辑器,Windows这个概念应该很熟悉。大部分文本编辑器具有显示多个窗口的能力。在Vim中,您同样可以拥有多个窗口。
让我们从终端再次打开file1.js:
vim file1.js
先前我说过,您看到的是file1.js的buffer。但这个说法并不完整,现在这句话得更正一下,您看到的是file1.js 的buffer通过 一个窗口 显示出来。窗口就是您查看的buffer所使用的视口。
先不忙急着退出Vim,在Vim中运行:
:split file2.js
现在您看到的是两个buffers通过 两个窗口 显示出来。上面的窗口显示的是file2.js的buffer。而下面的窗口显示的是file1.js的buffer。
如果您想在窗口之间导航,使用这些快捷键:
Ctrl-W H 移动光标到左边的窗口
Ctrl-W J 移动光标到下面的窗口
Ctrl-W K 移动光标到上面的窗口
Ctrl-W L 移动光标到右边的窗口
现在,在Vim中运行:
:vsplit file3.js
您现在看到的是三个窗口显示三个buffers。一个窗口显示file3.js的buffer,一个窗口显示file2.js的buffer,还有一个窗口显示file1.js的buffer。
您可以使多个窗口显示同一个buffer。当光标位于左上方窗口时,输入:
:buffer file2.js
现在两个窗口显示的都是file2.js的buffer。如果您现在在这两个窗口中的某一个输入内容,您会看到所有显示file2.jsbuffer的窗口都在实时更新。
要关闭当前的窗口,您可以按Ctrl-W C或输入:quit。当您关闭一个窗口后,buffers仍然会在列表中。(可以运行:buffers来确认这一点)。
这里有一些普通模式下关于窗口的命令:
Ctrl-W V 打开一个新的垂直分割的窗口
Ctrl-W S 打开一个新的水平分割的窗口
Ctrl-W C 关闭一个窗口
Ctrl-W O 除了当前窗口,关闭所有其他的窗口
另外,下面的列表列出了一些有用的关于windows的命令行命令
:vsplit filename 垂直分割当前窗口,并在新窗口中打开名为filename的文件。
:split filename 水平分割当前窗口,并在新窗口中打开名为filename的文件。
:new filename 创建一个新窗口并打开名为filename的文件。
花一点时间理解上面的知识。要了解更多信息,可以查看帮助:h window。
Tabs
Tabs就是windows的集合。它就像窗口的布局。在大部分的现代文本编辑器(还有现代互联网浏览器)中,一个tab意味着打开一个文件/页面,当您关闭标签,相应的文件/页面就消失了。但在Vim中,tab并不表示打开了一个文件。当您在Vim中关闭一个tab,您并不是关闭一个文件。您仅仅关闭了窗口布局。文件的数据依然存储在内存中的buffers中。
让我们运行几个命令看看Vim中tabs的功能。打开file1.js:
vim file1.js
若要在新tab中打开file2.js:
:tabnew file2.js
当然您可以按<Tab>让Vim自动补全 新tab 中将要打开的文件名(啰嗦几句,请理解作者的幽默 )。
下面的列表列出了一些有用的关于tab导航的命令:
:tabnew file.txt 在tab中打开一个文件
:tabclose 关闭当前tab
:tabnext 切换至下一个tab
:tabprevious 切换至前一个tab
:tablast 切换至最后一个tab
:tabfirst 切换至第一个tab
您可以输入gt切换到下一个标签页(对应的,可以用gT切换到前一个标签页)。您也可以传递一个数字作为参数给gt,这个数字是tab的编号。若想切换到第3个tab,输入3gt。
拥有多个tabs的好处是,您可以在不同的tab中使用不同的窗口布局。也许,您想让您的第1个tab包含3个垂直分割的窗口,然后让第2个tab为水平分割和垂直分割混合的窗口布局。tab是完成这件工作的完美工具!
若想让Vim启动时就包含多个tabs,您可以在终端中运行如下命令:
vim -p file1.js file2.js file3.js
三维移动
在windows之间移动就像在笛卡尔坐标系的二维平面上沿着X-Y轴移动。您可以使用Ctrl-W H/J/K/L移动到上面、右侧、下面、以及左侧的窗口。
在buffer之间移动就像在笛卡尔坐标系的Z轴上穿梭。想象您的buffer文件在Z轴上呈线性排列,您可以使用:bnext和bprevious在Z轴上一次一个buffer地遍历。您也可以使用:buffer 文件名/buffer编号在Z轴上跳转到任意坐标。
结合window和buffer的移动,您可以在 三维空间 中移动。您可以使用window导航命令移动到上面、右侧、下面、或左侧的窗口(X-Y平面导航)。因为每个window都可能包含了多个buffers,您可以使用buffer移动命令向前、向后移动(Z轴导航)。
用聪明的方法使用Buffers、Windows、以及Tabs
您已经学习了什么是buffers、windows、以及tabs,也学习了它们如何在Vim中工作。现在您对它们有了更好地理解,您可以把它们用在您自己的工作流程中。
每个人都有不同的工作流程,以下示例是我的工作流程:
- 首先,对于某个特定任务,我先使用buffers存储所有需要的文件。Vim就算打开很多buffer,速度一般也不会减慢。另外打开多个buffers并不会使我的屏幕变得拥挤。我始终只会看到1个buffer(假设我只有1个window),这可以让我注意力集中在1个屏幕上。当我需要使用其他文件时,可以快速切换至对应文件的buffer。
- 当比对文件、读文档、或追踪代码流时,我使用多窗口来一次查看多个buffers。我尽量保持屏幕上的窗口数不超过3个,因为超过3个屏幕将变得拥挤(我使用的是小型笔记本)。当相应工作完成后,我就关掉多余的窗口。窗口越少可以使注意力更集中。
- 我使用tmuxwindows来代替tabs。通常一次使用多个tmux窗口。比如,一个tmux窗口用来写客户端代码,一个用来写后台代码。
由于编辑风格不同,我的工作流程可能和您的工作流程不同,这没关系。您可以在实践中去探索适合您自己工作流程的编码风格。
第3章 打开和搜索文件
本章的目的是向您介绍如何在Vim中快速搜索,能够快速搜索是提高您的Vim工作效率的重要途径。当我解决了如何快速搜索文件这个问题后,我就决定改为完全使用Vim来工作。
本章划分为两个部分:一是如何不依赖插件搜索;二是使用fzf插件搜索。让我们开始吧!
打开和编辑文件
要在Vim中打开一个文件,您可以使用:edit。
:edit file.txt
如果file.txt已经存在,就会打开file.txtbuffer。如果file.txt不存在,会创建一个新buffer名为file.txt。
:edit命令支持使用<Tab>进行自动补全。比如,如果您的文件位于Rails应用控制器的用户控制器目录./app/controllers/users_controllers.rb内,您可以使用<Tab>对文件路径名进行快速扩展。
:edit a<Tab>c<Tab>u<Tab>
:edit可以接收通配符参数。*匹配当前目录下的任意文件。如果您只想查找当前目录下后缀名为.yml的文件:
:edit *.yml<Tab>
Vim将列出当前目录下所有.yml文件供您选择。
您可以使用**进行递归的搜索。如果您想查找当前项目文件夹下所有*.md文件,但您不知道在哪个目录,您可以这样做:
:edit **/*.md<Tab>
:edit可以用于运行netrw(Vim的内置文件浏览器)。使用方法是,给:edit一个目录参数而不是文件名就行了:
:edit .
:edit test/unit/
使用find命令搜索文件
您可以使用:find命令搜索文件。比如:
:find package.json
:find app/controllers/users_controller.rb
:find命令同样支持自动补全:
:find p<Tab> " to find package.json
:find a<Tab>c<Tab>u<Tab> " to find app/controllers/users_controller.rb
您可能注意到:find和:edit看起来很像。它们的区别是什么呢?
Find 和 Path
两者的区别在于,:find命令根据path选项配置的路径查找文件,而:edit不会。让我们了解一点关于path选项的知识。一旦您学会如何修改您的路径,:find命令能变成一个功能强大的搜索工具。先查看一下您的path是什么:
:set path?
默认情况下,您的path内容很可能是这样的:
path=.,/usr/include,,
.意思是在当前文件所在目录下搜索。(译者注:注意不是命令行输入pwd返回的当前目录,而是 当前所打开的文件 所在的目录),means to search in the current directory.(译者注:此处貌似作者有点小错误,逗号,应该是表示路径之间的分割符。连续的两个,,(两个逗号之间为空)才表示当前目录)/usr/include表示在C编译器头文件目录下搜索。
前两个配置非常重要,第3个现在可以被忽略。您这里应该记住的是:您可以修改您自己的路径。让我们假设您的项目结构是这样的:
app/
assets/
controllers/
application_controller.rb
comments_controller.rb
users_controller.rb
...
如果您想从根目录跳到users_controller.rb,您将不得不经过好几层目录(按好几次<Tab>)。一般说来,当您处理一个framework时,90%的时间您都在某个特定的目录下。在这种情况下,您只关心如何用最少的按键跳到controllers/目录。那么path设置可以减少这个途程。
您只需要将app/controllers/添加到当前path选项。以下是操作步骤:
:set path+=app/controllers/
现在您的路径已经更新,当您输入:find u<Tab>时,Vim将会在app/controllers/目录内搜索所有以”u”开头的文件。
如果您有一个嵌套的目录controllers/,比如app/controllers/account/users_controller.rb,Vim就找不到users_controllers了。您必须改为添加:set path+=app/controllers/**,这样自动补全才会找到users_controller.rb。这太棒了!您现在可以只需要按1次键就可找到users controller。
您可能会想将整个项目文件夹添加到path中,这样当您按<Tab>,Vim将在所有文件夹内搜索您要找的文件,就像这样:
:set path+=$PWD/**
$PWD 表示的是当前工作目录。如果您尝试将整个项目路径加到path中,并希望让所有文件名可以用<Tab>补全,虽然对于小项目没问题,但如果您的项目中包含大量文件时,这会显著降低您的搜索速度。我建议仅仅将您最常访问的文件/目录添加到path。(译者注:不知道是不是因为系统环境不一样的原因,译者使用的是windows下的Vim8.2,$PWD 这个环境变量在译者的vim中不起作用,必须在vimrc文件中添加一句let $PWD=getcwd()才行)。
您可以将set path+={您需要添加的目录}添加到您的vimrc文件中。更新path仅花费几秒钟,但可以为您的工作节省很多时间。
使用Grep命令在文件中搜索
如果您想在文件内部查找(搜索文件中的词句),您可以使用grep。Vim有两个方法可以完成这个工作:
- 内置grep (
:vim。没错,就是:vim,它是:vimgrep的简写)。 - 外部grep (
:grep)。
让我们首先仔细看看内置grep。:vim有以下语法:
:vim /pattern/ file
/pattern/是您要搜索的内容的正则表达式。file是文件参数。您可以传入多个参数。Vim将在文件中搜索所有匹配正则表达式的内容。类似于:find,您可以传入*和**通配符。
比如,要在app/controllers/目录下所有ruby文件(.rb)中,查找所有的”breakfast”字符串:
:vim /breakfast/ app/controllers/**/*.rb
输入上面的命令后,您将会被导航到第一个结果。Vim的vim搜索命令使用quickfix进行处理。要查看所有搜索结果,运行:copen会打开一个quickfix窗口。下面有一些有用的quickfix命令,可以让您提高效率:
:copen 打开quickfix窗口
:cclose 关闭quickfix窗口
:cnext 跳到下一个错误
:cprevious 跳到前一个错误
:colder 跳到旧的错误列表
:cnewer 跳到新的错误列表
要了解更多关于quickfix的信息,使用:h quickfix查看帮助信息。
您可能注意到运行内置grep(:vim)命令时,如果匹配结果数量较多时系统速度会变慢。这是因为Vim将每一个搜索结果读入内存。Vim加载每一个匹配的文件就像它们被编辑一样。如果Vim查到大量文件,它将消耗很多内存。
让我们谈谈外置grep。默认情况下,它使用终端命令grep。要想在app/controllers/目录中搜索字符串”lunch”,您可以这样做:
:grep -R "lunch" app/controllers/
注意这里不是使用/pattern/,它遵循的是终端grep的语法"pattern",它同样使用’quickfix’来显示所有的匹配结果。
Vim使用grepprg变量来决定运行:grep时,应该使用哪个外部程序。所以您并不是非得使用终端的grep命令。稍后我将为您演示如何改变外部grep程序的默认值。
用Netrw浏览文件
netrw是Vim的内置文件浏览器,当查看项目的目录结构时很有用。要运行netrw,您需要在您的.vimrc中做以下设置:
set nocp
filetype plugin on
由于netrw是一个很宽泛的话题,我将紧紧介绍它的基本用法,这应该已经足够了。您可以在启动Vim时运行netrw,只需要传给Vim一个目录参数(而不是文件参数)就行了。比如:
vim .
vim src/client/
vim app/controllers/
要想从Vim内部运行netrw,您可以使用:edit命令,传给他一个目录而不是文件名:
:edit .
:edit src/client/
:edit app/controllers/
也有其他方法,不需要传递目录参数就运行netrw窗口:
:Explore 从当前文件启动netrw。
:Sexplore Sex_Plore?不是开玩笑:),在顶部水平分割的窗口打开netrw。
:Vexplore 在左侧垂直分割的窗口打开netrw。
您可以使用Vim动作(motions,在后面的章节中将详细讲述)在netrw中导航。如果您要创建、删除、重命名文件或文件夹,下面有一些关于netrw的有用命令:
% 创建新文件
d 创建新目录
R 重命名文件/目录
D 删除文件/目录
:h netrw 的信息非常复杂,如果您有时间可以看看。
如果您觉得 netrw 过于单调乏味,vim-vinegar是netrw的一个改进插件。如果您想找一个不同的文件浏览器,NERDTree 是一个很好的选择。去看看吧。
Fzf插件
您现在已经学会了如何使用Vim的内置工具去搜索文件,那么让我们学习一下如何用插件实现这些功能吧。
现代文本编辑器相比Vim,有一个功能设计得很好,那就是文件搜索和模糊搜索的简化。在本章的下半部分,我将向您演示如何使用fzf.vim插件,在Vim中轻松实现功能强大的搜索功能。
安装
首先,确保您下载了fzf和ripgrep。按照它们在github仓库上的指令一步步做。成功安装后,命令fzf和rg应该就可以用了。
Ripgrep是一个类似grep(从名字上就看得出)的搜索工具。一般说来,它比grep要快,而且还有很多有用的特性。Fzf是一个多用途的命令行模糊搜索工具,您可以讲它与其他命令联合起来使用,包括ripgrep。联合起来后,它们成为一个功能强大的搜索工具。
Fzf默认并不使用ripgrep,所以我们需要设置FZF_DEFAULT_COMMAND变量告诉fzf使用ripgrep命令。在我的.zshrc(如果您用bash,应该是.bashrc)文件内,我有以下设置:
if type rg &> /dev/null; then
export FZF_DEFAULT_COMMAND='rg --files'
export FZF_DEFAULT_OPTS='-m'
fi
注意FZF_DEFAULT_OPTS变量中的-m。这个设置允许我们按下<Tab或<Shift-Tab>后进行多重选择。如果仅想让fzf在Vim中能够工作,这个设置不是必须的,但我认为这是一个有用的设置。当您想在多个文件中执行搜索和替换,进行少量修改时,它会很方便。fzf命令可以接收很多标志,但我不会再这里讲。要想了解更多信息,可以查看fzf’s 仓库,或者使用man fzf。要想让fzf使用ripgrep,您至少得有这个设置export FZF_DEFAULT_COMMAND='rg'。
安装好了fzf和ripgrep后,让我们再安装fzf的插件。在这个例子中,我使用的是vim-plug插件管理器,当然您可以使用其他插件管理器。
将下列配置添加到您的.vimrc中。因为您需要使用fzf.vim插件。(同样是由fzf的作者在维护)
Plug 'junegunn/fzf.vim'
Plug 'junegunn/fzf', { 'do': { -> fzf#install() } }
添加后,您需要打开vim,运行:PlugInstall。这条命令将会安装所有您在vimrc文件中定义了但尚未安装的插件。 在我的例子中,将会安装fzf.vim和fzf。
要了解更多关于此插件的信息,您可以查看fzf.vim 的仓库。
Fzf的语法
要想高效的使用fzf,您首先得了解一些fzf的基础语法。幸运的是,这个列表比较短:
^表示前缀精确匹配。要搜索一个以”welcome”开头的短语:^welcom。$表示后缀精确匹配。要搜索一个以”my friends”结尾的短语:friends$。'表示精确匹配。要搜索短语”welcom my friends”:'welcom my friends。|表示”或者”匹配。要搜索”friends”或”foes”:friends | foes。!表示反向匹配。要搜索一个包含”welcome”但不包含”friends”的短语:welcome !friends。
您可以混合起来使用。比如,^hello | ^welcome friends$将搜索以”welcome”或”hello”开头,并且以”friends”结束的短语。
查找文件
要想在Vim内使用fzf.vim插件搜索文件,您可以使用:Files方法。在Vim中运行:Files,您将看到fzf搜索提示符。
因为您将频繁地使用这个命令,最好建立一个键盘映射,我把它映射到Ctrl-f。在我的vimrc配置中,有这个设置:
nnoremap <silent> <C-f> :Files<CR>
在文件中查找
要想在文件内部搜索,您可以使用:Rg命令。
同样,因为您可能将频繁的使用这个命令,让我们给它一个键盘映射。我的映射在<Leader>f。
nnoremap <silent> <Leader>f :Rg<CR>
其他搜索
Fzf.vim提供了许多其他命令。这里我不会一个个仔细讲,您可以去这里查看更多信息。
这是我的fzf键盘映射:
nnoremap <silent> <Leader>b :Buffers<CR>
nnoremap <silent> <C-f> :Files<CR>
nnoremap <silent> <Leader>f :Rg<CR>
nnoremap <silent> <Leader>/ :BLines<CR>
nnoremap <silent> <Leader>' :Marks<CR>
nnoremap <silent> <Leader>g :Commits<CR>
nnoremap <silent> <Leader>H :Helptags<CR>
nnoremap <silent> <Leader>hh :History<CR>
nnoremap <silent> <Leader>h: :History:<CR>
nnoremap <silent> <Leader>h/ :History/<CR>
将Grep替换为Rg
正如前面提到的,Vim有两种方法在文件内搜索::vim和:grep。您可以使用grepprg这个关键字重新指定:grep使用的外部搜索工具。我将向您演示如何设置Vim,使得当运行:grep命令时,使用ripgrep代替终端的grep。
现在,让我们设置grepprg来使:grep使用ripgrep。将下列设置添加到您的vimrc:
set grepprg=rg\ --vimgrep\ --smart-case\ --follow
上面的一些选项可以随意修改!要想了解更多关于这些选项的含义,请使用man rg了解详情。
当您更新grepprg选项后,现在当您运行:grep,它将实际运行rg --vimgrep --smart-case --follow而不是grep。如果您想使用ripgrep搜索”donut”,您可以运行一条更简洁的命令:grep "donut",而不是:grep "donut" . -R
就像老的:grep一样,新的:grep同样使用quickfix窗口来显示结果。
您可能好奇,“很好,但我从没在Vim中使用过:grep,为什么我不能直接使用:Rg命令在文件中搜索呢?究竟什么时候我必须使用:grep?”。
这个问题问得很好。在Vim中,当您需要在多个文件中执行搜索和替换时,您可能必须使用:grep这个命令。我马上就会讲这个问题。
在多文件中搜索和替换
现代文本编辑器,比如VSCode中,在多个文件中搜索和替换一个字符串是很简单的事情。在这一节,我将向您演示如何在Vim中轻松实现这个。
第一个方法是在您的项目中替换 所有 的匹配短句。您得使用:grep命令。如果您想将所有”pizza”替换为”donut”,下面是操作方法:
:grep "pizza"
:cfdo %s/pizza/donut/g | update
让我们来分析一下这条命令:
:grep pizza使用ripgrep去搜索所有”pizza”(顺带说一句,就算您不给grepprg重新赋值让它使用ripgrep,这条命令依然有效,但您可能不得不使用:grep "pizza" . -R命令,而不是:grep "pizza")。:cfdo会在您的quickfix列表中所有文件里,执行您传递给它的命令。在这个例子中,您的命令是一条替换命令%s/pizza/donut/g。管道符号(|)是一个链接操作符。命令update在每个文件被替换后,立刻保存。在后面的章节中,我将深入介绍替换命令。
第二个方法是在您选择文件中执行搜索和替换。用这个方法,您可以手动选择您想执行搜索和替换的文件。下面是操作方法:
- 首先清空您的buffer。让您的buffer列表仅包含您所需要的文件,这一点很有必要。您可以重启Vim,也可以运行
:%bd | e#命令(%bd关闭所有buffer,而e#打开您当前所在的文件)。 - 运行
:Files。 - 选择好您想搜索-替换的文件。要选择多个文件,使用
<Tab>或<Shift-Tab>。当然,您必须使多文件标志(-m)位于FZF_DEFAULT_OPTS中。 - 运行
:bufdo %s/pizza/donut/g | update。命令:bufdo %s/pizza/donut/g | update看起来和前面的:cfdo %s/pizza/donut/g | update很像,区别在于,(:cfdo)替换所有quickfix中的实体,而(:bufdo)替换所有buffer中的实体。
用聪明的方法学习搜索
在文本编辑时,搜索是一个很实用的技巧。学会在Vim中如何搜索,将显著提高您的文本编辑工作流程效率。
Fzf.vim插件就像一个游戏规则改变者。我无法想象使用Vim没有它的情景。当最开始使用Vim时,如果有一个好的搜索工具,我想是非常重要的。我看见很多人过渡到Vim时的艰难历程,就是因为Vim缺少了现代编辑器所拥有的一些关键功能特性,比如简单快捷且功能强大的搜索功能。我希望本章将帮助您更轻松地向Vim过渡。
您同时也看到了Vim的扩展性,即使用插件或外部程序扩展搜索功能的能力。将来,记住您想在Vim中拓展的功能。很有可能已经有人写好了相关插件,已经有现成的程序了。下一章,您将学习Vim中非常重要的主题:Vim语法。
第4章 Vim 语法
刚接触Vim时很容易被Vim许多复杂的命令吓到,如果你看到一个Vim的用户使用gUfV或1GdG,你可能不能立刻想到这些命令是在做什么。这一章中,我将把Vim命令的结构拆分成一个简单的语法规则进行讲解。
这一章将是本书中最重要的一章,一旦你理解了Vim命令的语法结构,你将能够和Vim”说话”。注意,在这一章中当我讨论Vim语言时,我讨论并不是 Vimscript(Vim自带的插件编写和自定义设置的语言),这里我讨论的是Vim中normal模式的下的命令的通用规则。
如何学习一门语言
我并不是一个英语为母语的人,当我13岁移民到美国时我学习的英语,我会通过做三件事情建立我的语言能力:
- 学习语法规则
- 扩展我的词汇量
- 练习,练习,练习
同样的,为了说好Vim语言,你需要学习语法规则,增加词汇量,并且不断练习直到你可以把执行命令变成肌肉记忆。
语法规则
你只需要知道一个Vim语言的语法规则:
verb + noun # 动词 + 名词
这就类似与在英语中的祈使句:
- “Eat(verb) a donut(noun)”
- “Kick(verb) a ball(noun)”
- “Learn(verb) the Vim Editor(noun)”
现在你需要的就是用Vim中基本的动词和名字来建立你的词汇表
名词(动作 Motion)
我们这里将 动作 Motion 作为名词, 动作Motion用来在Vim中到处移动。下面列出了一些常见的动作的例子:
h 左
j 下
k 上
l 右
w 向前移动到下一个单词的开头
} 跳转到下一个段落
$ 跳转到当前行的末尾
在之后的章节你将学习更多的关于动作的内容,所以如果你不理解上面这些动作也不必担心。
动词(操作符 Operator)
根据:h operator,Vim共有16个操作符,然而根据我的经验,学习这3个操作符在80%的情况下就已经够用了
y yank(复制)
d delete(删除)
c change 删除文本,将删除的文本存到寄存器中,进入插入模式
顺带说一句,当你yank一段文本后,您可以使用p将它粘贴到光标后,或使用P粘贴到光标前。
动词(操作符 Operator)和名词(动作 motions)的结合
现在你已经知道了基本的动词和名词,我们来用一下我们的语法规则,动词和名词的结合!假设你有下面这段文本:
const learn = "Vim";
- 复制当前位置到行尾的所有内容:
y$ - 删除当前位置到下一个单词的开头:
dw - 修改当前位置到这个段落的结尾:
c}
动作 motions也接受数字作为参数(这个部分我将在下个章节展开),如果你需要向上移动3行,你可以用3k代替按3次k,数字可应用在Vim语法中。
- 向左拷贝2个字符:
y2h - 删除后两个单词:
d2w - 修改后面两行:
c2j
目前,你也许需要想很久才能完成一个简单的命令,不过我刚开始时也是这样,我也经历过类似的挣扎的阶段但是不久我的速度就快了起来,你也一样。唯一途径就是重复、重复再重复。
作为补充,行级的 操作符 operations (作用在整行中的操作符)在文本编辑中和其他的 操作符 一样,Vim允许你通过按两次 操作符使它执行行级的操作,例如dd,yy,cc来执行删除,复制或修改整个行。您可以使用其他operations试一下(比如gUgU)。
666!从这可以看出Vim命令的一种执行模式。但是到目前为止还没有结束,Vim有另一种类型的名词:文本对象(text object)
更多名词(文本对象 Text Objects)
想象一下你现在正在某个被括号包围的文本中例如(hello Vim),你现在想要删掉括号中的所有内容,你会怎样快速的完成它?是否有一种方法能够把括号中内容作为整体删除呢?
答案是有的。文本通常是结构化的,特别是代码中,文本经常被放置在小括号、中括号、大括号、引号等当中。Vim提供了一种处理这种结构的文本对象的方法。
文本对象可以被 操作符 operations 使用,这里有两类文本对象:
i + object 内部文本对象
a + object 外部文本对象
内部文本对象选中的部分不包含包围文本对象的空白或括号等,外部文本对象则包括了包围内容的空白或括号等对象。外部对象总是比内部对象选中的内容更多。如果你的光标位于一对括号内部,例如(hello Vim)中:
- 删除括号内部的内容但保留括号:
di( - 删除括号以及内部的内容:
da(
让我们看一些别的例子,假设你有这样一段Javascript的函数,你的光标停留在”Hello”中的”H”上:
const hello = function() {
console.log("Hello Vim");
return true;
}
- 删除整个”Hello Vim”:
di( - 删除整个函数(被{}包含):
di{ - 删除”Hello”这个词:
diw
文本对象很强大因为你可以在同一个位置指向不同的内容,可以删除一对小括号中的文本,也可以是当前大括号中的函数体,也可以是当前单词。这一点也很好记忆,当你看到di(,di{和diw时,你也可以很好的意识到他们表示的是什么:小括号,大括号,单词。
让我们来看最后一个例子。假设你有这样一些html的标签的文本:
<div>
<h1>Header1</h1>
<p>Paragraph1</p>
<p>Paragraph2</p>
</div>
如果你的光标位于”Header1”文本上:
- 删除”Header1”:
dit - 删除
<h1>Header1</h1>:dat
如果你的光标在”div”文本上:
- 删除
h1和所有p标签的行:dit - 删除所有文本:
dat - 删除”div”:
di<
下面列举的一些通常见到的文本对象:
w 一个单词
p 一个段落
s 一个句子
(或) 一对()
{或} 一对{}
[或] 一对[]
<或> 一对<>
t XML标签
" 一对""
' 一对''
` 一对``
你可以通过:h text-objects了解更多
结合性和语法
在学习Vim的语法之后,让我们来讨论一下Vim中的结合性以及为什么在文本编辑器中这是一个强大的功能。
结合性意味着你有很多可以组合起来完成更复杂命令的普通命令,就像你在编程中可以通过一些简单的抽象建立更复杂的抽象,在Vim中你可以通过简单的命令的组合执行更复杂的命令。Vim语法正是Vim中命令的可结合性的体现。
Vim的结合性最强大之处体现在它和外部程序结合时,Vim有一个 过滤操作符!可以用外部程序过滤我们的文本。假设你有下面这段混乱的文本并且你想把它用tab格式化的更好看的一些:
Id|Name|Cuteness
01|Puppy|Very
02|Kitten|Ok
03|Bunny|Ok
这件事情通过Vim命令不太容易完成,但是你可以通过终端提供的命令column很快的完成它,当你的光标位于”Id”上时,运行!}column -t -s "|",你的文本就变得整齐了许多:
Id Name Cuteness
01 Puppy Very
02 Kitten Ok
03 Bunny Ok
让我们分解一下上面那条命令,动词是!(过滤操作符),名词是}(到下一个段落)。过滤操作符!接受终端命令作为另一个参数,因此我把column -t -s "|"传给它。我不想详细描述column是如何工作的,但是总之它格式化了文本。
假设你不止想格式化你的文本,还想只展示Ok结尾的行,你知道awk命令可以做这件事情,那么你可以这样做:
!}column -t -s "|" | awk 'NR > 1 && /Ok/{print $0}'
结果如下:
02 Kitten Ok
03 Bunny Ok
666!管道竟然在Vim中也能起作用。
这就是Vim的结合性的强大之处。你知道的动词 操作符,名词 动作,终端命令越多,你组建复杂操作的能力成倍增长。
换句话说,假设你只知道四个动作:w, $, }, G和删除操作符(d),你可以做8件事:按四种方式移动(w, $, }, G)和删除4种文本对象(dw, d$, d}, dG)。如果有一天你学习了小写变大写的操作符(gU),你的Vim工具箱中多的不是1种工具,而是4种:gUw, gU$, gU}, gUG。现在你的Vim工具箱中就有12种工具了。如果你知道10个动作和5个操作符,那么你就有60种工具(50个操作+10个移动)。另外,行号动作(nG)给你了n种动作,其中n是你文件中的行数(例如前往第5行,5G)。搜索动作(/)实际上给你带来无限数量的动作因为你可以搜索任何内容。你知道多少终端命令,外部命令操作符(!)就给你了多少种过滤工具。使用Vim这种能够组合的工具,所有你知道的东西都可以被串起来完成更复杂的操作。你知道的越多,你就越强大。
这种具有结合性的行为也正符合Unix的哲学:一个命令做好一件事。动作只需要做一件事:前往X。操作符只需要做一件事:完成Y。通过结合一个操作符和一个动作,你就获得了YX:在X上完成Y。
甚至,动作和操作符都是可拓展的,你可以自己创造动作和操作符去丰富你的Vim工具箱,Vim-textobj-user插件允许你创建自己的文本对象,同时包含有一系列定义好的文本对象。
另外,如果你不知道我刚才使用的column和awk命令也没有关系,重要的是Vim可以和终端命令很好的结合起来。
聪明地学习语法
你刚刚学完Vim唯一的语法规则:
verb + noun
我学Vim中最大的”AHA moment”之一是当我刚学完大写命令(gU)时,想要把一个单词变成大写,我本能的运行了gUiW,它居然成功了,我光标所在的单词都大写了。我正是从那是开始理解Vim的。我希望你也会在不久之后有你自己的”AHA moment”,如果之前没有的话。
这一章的目标是向你展现Vim中的verb+noun模式,因此之后你就可以像学习一门新的语言一样渐进的学习Vim而不是死记每个命令的组合。
学习这种模式并且理解其中的含义,这是聪明的学习方式。
第5章 在文件中移动
一开始,通过键盘移动会让你感觉特别慢特别不自在,但是不要放弃!一旦你习惯了它,比起鼠标你可以更快的在文件中去到任何地方。
这一章,你将学习必要的移动以及如何高效的使用它们。 记住,这一章所讲的并不是Vim的全部移动命令(motions),我们的目标是介绍有用的移动来快速提高效率。 如果你需要学习更多的移动命令,查看:h motion.txt。
字符导航
最基本的移动单元是上下左右移动一个字符。
h 左
j 下
k 上
l 右
你也可以通过方向键进行移动,如果你只是初学者,使用任何你觉得最舒服的方法都没有关系。
我更喜欢hjkl因为我的右手可以保持在键盘上的默认姿势,这样做可以让我更快的敲到周围的键。 为了习惯它,我实际上在刚开始的时候通过~/.vimrc关闭了方向键:
noremap <Up> <NOP>
noremap <Down> <NOP>
noremap <Left> <NOP>
noremap <Right> <NOP>
也有一些插件可以帮助改掉这个坏习惯,其中有一个叫vim-hardtime。 让我感到惊讶的是,我只用了几天就习惯了使用hjkl。
另外,如果你想知道为什么Vim使用hjkl进行移动,这实际上是因为Bill Joy写VI用的Lear-Siegler ADM-3A终端没有方向键,而是把hjkl当做方向键。
如果你想移动到附近的某个地方,比如从一个单词的一个部分移动到另一个部分,我会使用h和l。 如果我需要在可见的范围内上下移动几行,我会使用j和k。 如果我想去更远的地方,我倾向于使用其他移动命令。
相对行号
我觉得设置number和relativenumber非常有用,你可以在~/.vimrc中设置:
set relativenumber number
这将会展示当前行号和其他行相对当前行的行号。
为什么这个功能有用呢?这个功能能够帮助我知道我离我的目标位置差了多少行,有了它我可以很轻松的知道我的目标行在我下方12行,因此我可以使用12j去前往。 否则,如果我在69行,我的目标是81行,我需要去计算81-69=12行,这太费劲了,当我需要去一个地方时,我需要思考的部分越少越好。
这是一个100%的个人偏好,你可以尝试relativenumber/norelativenumber,number/nonumber 然后选择自己觉得最有用的。
对移动计数
在继续之前,让我们讨论一下”计数”参数。 一个移动(motion)可以接受一个数字前缀作为参数,上面我提到的你可以通过12j向下移动12行,其中12j中的12就是计数数字。
你使用带计数的移动的语法如下:
[计数] + 移动
你可以把这个应用到所有移动上,如果你想向右移动9个字符,你可以使用9l来代替按9次l。 当你学到了更多的动作时,你都可以试试给定计数参数。
单词导航
我们现在移动一个更长的单元:单词(word)。 你可以通过w移动到下一个单词的开始,通过e移动到下一个单词的结尾,通过b移动到上一个单词的开始,通过ge移动到前一个单词的结尾。
另外,为了和上面说的单词(word)做个区分,还有一种移动的单元:词组(WORD)。 你可以通过W移动到下一个词组的开始,通过E移动到下一个词组的结尾,通过B移动到前一个词组的开头,通过gE移动到前一个词组的结尾。 为了方便记忆,所以我们选择了词组和单词这两个词,相似但有些区分。
w 移动到下一个单词的开头
W 移动到下一个词组的开头
e 移动到下一个单词的结尾
E 移动到下一个词组的结尾
b 移动到前一个单词的开头
B 移动到前一个词组的开头
ge 移动到前一个单词的结尾
gE 移动到前一个词组的结尾
词组和单词到底有什么相同和不同呢?单词和词组都按照非空字符被分割,一个单词指的是一个只包含a-zA-Z0-9字符串,一个词组指的是一个包含除了空字符(包括空格,tab,EOL)以外的字符的字符串。 你可以通过:h word和:h WORD了解更多。
例如,假如你有下面这段内容:
const hello = "world";
当你光标位于这行的开头时,你可以通过l走到行尾,但是你需要按21下,使用w,你需要6下,使用W只需要4下。 单词和词组都是短距离移动的很好的选择。
然而,之后你可以通过当前行导航只按一次从c移动到;。
当前行导航
当你在进行编辑的时候,你经常需要水平地在一行中移动,你可以通过0跳到本行第一个字符,通过$跳到本行最后一个字符。 另外,你可以使用^跳到本行第一个非空字符,通过g_跳到本行最后一个非空字符。 如果你想去当前行的第n列,你可以使用n|。
0 跳到本行第一个字符
^ 跳到本行第一个非空字符
g_ 跳到本行最后一个非空字符
$ 跳到本行最后一个字符
n| 跳到本行第n列
你也可以在本行通过f和t进行行内搜索,f和t的区别在于f会停在第一个匹配的字母上,t会停在第一个匹配的字母前。 因此如果你想要搜索并停留在”h”上,使用fh。 如果你想搜索第一个”h”并停留在它的前一个字母上,可以使用th。 如果你想去下一个行内匹配的位置,使用;,如果你想去前一个行内匹配的位置,使用,。
F和T是f和t对应的向后搜索版本。如果想向前搜索”h”,可以使用Fh,使用;,保持相同的搜索方向搜索下一个匹配的字母。 注意,;不是总是向后搜索,;表示的是上一次搜索的方向,因此如果你使用的F,那么使用;时将会向前搜索使用,时向后搜索。
f 在同一行向后搜索第一个匹配
F 在同一行向前搜索第一个匹配
t 在同一行向后搜索第一个匹配,并停在匹配前
T 在同一行向前搜索第一个匹配,并停在匹配前
; 在同一行重复最近一次搜索
, 在同一行向相反方向重复最近一次搜索
回到上一个例子:
const hello = "world";
当你的光标位于行的开头时,你可以通过按一次键$去往行尾的最后一个字符”;”。 如果想去往”world”中的”w”,你可以使用fw。 一个建议是,在行内目标附近通过寻找重复出现最少的字母例如”j”,”x”,”z”来前往行中的该位置更快。
句子和段落导航
接下来两个移动的单元是句子和段落。
首先我们来聊聊句子。 一个句子的定义是以.!?和跟着的一个换行符或空格,tab结尾的。 你可以通过)和(跳到下一个和上一个句子。
( 跳到前一个句子
) 跳到下一个句子
让我们来看一些例子,你觉得哪些字段是句子哪些不是? 可以尝试在Vim中用(和)感受一下。
I am a sentence. I am another sentence because I end with a period. I am still a sentence when ending with an exclamation point! What about question mark? I am not quite a sentence because of the hyphen - and neither semicolon ; nor colon :
There is an empty line above me.
另外,如果你的Vim中遇到了无法将一个以.结尾的字段并且后面跟着一个空行的这种情况判断为一个句子的问题,你可能处于compatible的模式。 运行:set nocompatible可以修复。 在Vi中,一个句子是以两个空格结尾的,你应该总是保持的nocompatible的设置。
接下来,我们将讨论什么是段落。 一个段落可以从一个空行之后开始,也可以从段落选项(paragraphs)中”字符对”所指定的段落宏的每个集合开始。
{ 跳转到上一个段落
} 跳转到下一个段落
如果你不知道什么是段落宏,不用担心,重要的是一个段落总是以一个空行开始和结尾, 在大多数时候总是对的。
我们来看这个例子。 你可以尝试着使用}和{进行导航,也可以试一试()这样的句子导航。
Hello. How are you? I am great, thanks!
Vim is awesome.
It may not easy to learn it at first...- but we are in this together. Good luck!
Hello again.
Try to move around with ), (, }, and {. Feel how they work.
You got this.
你可以通过:h setence和:h paragraph了解更多。
匹配导航
程序员经常编辑含有代码的文件,这种文件内容会包含大量的小括号,中括号和大括号,并且可能会把你搞迷糊你当前到底在哪对括号里。 许多编程语言都用到了小括号,中括号和大括号,你可能会迷失于其中。 如果你在它们中的某一对括号中,你可以通过%跳到其中一个括号或另一个上(如果存在)。 你也可以通过这种方法弄清你是否各个括号都成对匹配了。
% Navigate to another match, usually works for (), [], {}
我们来看一段Scheme代码示例因为它用了大量的小括号。 你可以在括号中用%移动
(define (fib n)
(cond ((= n 0) 0)
((= n 1) 1)
(else
(+ (fib (- n 1)) (fib (- n 2)))
)))
我个人喜欢使用类似vim-rainbow这样的可视化指示插件来作为%的补充。 通过:h %了解更多。
行号导航
你可以通过nG调到行号为n的行,例如如果你想跳到第7行,你可以使用7G,跳到第一行使用gg或1G,跳到最后一行使用G。
有时你不知道你想去的位置的具体行号,但是知道它大概在整个文件的70%左右的位置,你可以使用70%跳过去,可以使用50%跳到文件的中间。
gg 跳转到第一行
G 跳转到最后一行
nG 跳转到第n行
n% 跳到文件的n%
另外,如果你想看文件总行数,可以用CTRL-g查看。
窗格导航
为了移动到当前窗格的顶部,中间,底部,你可以使用H,M和L。
你也可以给H和L传一个数字前缀。 如果你输入10H你会跳转到窗格顶部往下数10行的位置,如果你输入3L,你会跳转到距离当前窗格的底部一行向上数3行的位置。
H 跳转到屏幕的顶部
M 跳转到屏幕的中间
L 跳转到屏幕的底部
nH 跳转到距离顶部n行的位置
nL 跳转到距离底部n行的位置
滚动
在文件中滚动,你有三种速度可以选择: 滚动一整页(CTRL-F/CTRL-B),滚动半页(CTRL-D/CTRL-U),滚动一行CTRL-E/CTRL-Y)。
Ctrl-e 向下滚动一行
Ctrl-d 向下滚动半屏
Ctrl-f 向下滚动一屏
Ctrl-y 向上滚动一行
Ctrl-u 向上滚动半屏
Ctrl-b 向上滚动一屏
你也可以相对当前行进行滚动
zt 将当前行置于屏幕顶部附近
zz 将当前行置于屏幕中央
zb 将当前行置于屏幕底部
搜索导航
通常,你已经知道这个文件中有一个字段,你可以通过搜索导航非常快速的定位你的目标。 你可以通过/向下搜索,也可以通过?向上搜索一个字段。 你可以通过n重复最近一次搜索,N向反方向重复最近一次搜索。
/ 向后搜索一个匹配
? 向前搜素一个匹配
n 重复上一次搜索(和上一次方向相同)
N 重复上一次搜索(和上一次方向相反)
假设你有一下文本:
let one = 1;
let two = 2;
one = "01";
one = "one";
let onetwo = 12;
你可以通过/let搜索”let”,然后通过n快速的重复搜索下一个”let”,如果需要向相反方向搜索,可以使用N。 如果你用?let搜索,会得到一个向前的搜索,这时你使用n,它会继续向前搜索,就和?的方向一致。(N将会向后搜索”let”)。
你可以通过:set hlsearch设置搜索高亮。 这样,当你搜索/let,它将高亮文件中所有匹配的字段。 另外,如果你通过:set incsearch设置了增量搜索,它将在你输入时不断匹配的输入的内容。 默认情况下,匹配的字段会一直高亮到你搜索另一个字段,这有时候很烦人,如果你希望取消高亮,可以使用:nohlsearch。 因为我经常使用这个功能,所以我会设置一个映射:
nnoremap <esc><esc> :noh<return><esc>
你可以通过*快速的向前搜索光标下的文本,通过#快速向后搜索光标下的文本。 如果你的光标位于一个字符串”one”上,按下*相当于/\<one\>。
/\<one\>中的\<和\>表示整词匹配,使得一个更长的包含”one”的单词不会被匹配上,也就是说它会匹配”one”,但不会匹配”onetwo”。 如果你的光标在”one”上并且你想向后搜索完全或部分匹配的单词,例如”one”和”onetwo”,你可以用g*替代*。
* 向后查找光标所在的完整单词
# 向前查找光标所在的完整单词
g* 向后搜索光标所在的单词
g# 向前搜索光标所在的单词
位置标记
你可以通过标记保存当前位置并在之后回到这个位置,就像文本编辑中的书签。 你可以通过mx设置一个标记,其中x可以是a-zA-Z。 有两种办法能回到标记的位置: 用`x精确回到(行和列),或者用'x回到行级位置。
ma 用a标签标记一个位置
`a 精确回到a标签的位置(行和列)
'a 跳转到a标签的行
a-z的标签和A-Z的标签存在一个区别,小写字母是局部标签,大写字母是全局标签(也称文件标记)。
我们首先说说局部标记。 每个buffer可以有自己的一套局部标记,如果打开了两个文件,我可以在第一个文件中设置标记”a”(ma),然后在另一个文件中设置另一个标记”a”(ma)。
不像你可以在每个buffer中设置一套局部标签,你只能设置一套全局标签。 如果你在myFile.txt中设置了标签mA,下一次你在另一个文件中设置mA时,A标签的位置会被覆盖。 全局标签有一个好处就是,即使你在不同的项目红,你也可以跳转到任何一个全局标签上,全局标签可以帮助你在文件间切换。
使用:marks查看所有标签,你也许会注意到除了a-zA-Z以外还有别的标签,其中有一些例如:
'' 在当前buffer中跳转回到上一次跳转前的最后一行
`` 在当前buffer中跳转回到上一次跳转前的最后一个位置
`[ 跳转到上一次修改或拷贝的文本的开头
`] 跳转到上一次修改或拷贝的文本的结尾
`< 跳转到最近一次可视模式下选择的部分的开头
`> 跳转到最近一次可视模式下选择的部分的结尾
`0 跳转到退出Vim前编辑的最后一个文件
除了上面列举的,还有更多标记,我不会在这一一列举因为我觉得它们很少用到,不过如果你很好奇,你可以通过: marks查看。
跳转
最后,我们聊聊Vim中的跳转你通过任意的移动可以在不同文件中或者同一个的文件的不同部分间跳转。 然而并不是所有的移动都被认为是一个跳转。 使用j向下移动一行就不被看做一个跳转,即使你使用10j向下移动10行,也不是一个跳转。 但是你通过10G去往第10行被算作一个跳转。
' 跳转到标记的行
` 跳转到标记的位置(行和列)
G 跳转到行
/ 向后搜索
? 向前搜索
n 重复上一次搜索,相同方向
N 重复上一次搜索,相反方向
% 查找匹配
( 跳转上一个句子
) 跳转下一个句子
{ 跳转上一个段落
} 跳转下一个段落
L 跳转到当前屏幕的最后一行
M 跳转到当前屏幕的中间
H 跳转到当前屏幕的第一行
[[ 跳转到上一个小节
]] 跳转到下一个小节
:s 替换
:tag 跳转到tag定义
我不建议你把上面这个列表记下来,一个大致的规则是,任何大于一个单词或超过当前行导航的移动都可能是一个跳转。 Vim保留了你移动前位置的记录,你可以通过:jumps查看这个列表,如果想了解更多,可以查看:h jump-motions。
为什么跳转有用呢? 因为你可以在跳转列表中通过Ctrl-o和Ctrl-i在记录之间向上或向下跳转到对应位置。 你可以在不同文件中进行跳转,这将是我之后会讲的部分。
聪明地学习导航
如果你是Vim的新手,这有很多值得你学,我不期望任何人能够立刻记住每样知识点,做到不用思考就能执行这需要一些时间。
我想,最好的开始的办法就是从一些少量的必要的移动开始记。 我推荐你从h,j,k,l,w,b,G,/,?,n开始,不断地重复这10个移动知道形成肌肉记忆,这花不了多少时间。
为了让你更擅长导航,我有两个建议:
- 注意重复的动作。 如果你发现你自己在重复的使用
l,你可以去找一个方法让你前进的更快,然后你会发现你可以用w在单词间移动。 如果你发现你自己的重复的使用w,你可以看看是否有一种方法能让你直接到行尾,然后你会想到可以用$。 如果你可以口语化的表达你的需求,Vim中大概就会有一种方法去完成它。 - 当你学习任何一个新的移动时,多需要花一定的时间直到你可以不经过思考直接完成它。
最后,为了提高效率你不需要知道所有的Vim的命令,大多数Vim用户也都不知道,你只需要学习当下能够帮助你完成任务的命令。
慢慢来,导航技巧是Vim中很重要的技巧,每天学一点并且把它学好。
第6章 输入模式
输入模式是大部分文本编辑器的默认模式,在这个模式下,所敲即所得。
尽管如此,这并不代表输入模式没什么好学的。Vim的输入模式包含许多有用功能。在这一章节中,你将能够学到如何利用Vim输入模式中的特性来提升你的输入效率。
进入输入模式的方法
我们有很多方式从普通模式进入输入模式,下面列举出了其中的一些方法:
i 从光标之前的位置开始输入文本
I 从当前行第一个非空字符之前的位置之前开始输入文本
a 在光标之后的位置追加文本
A 在当前行的末尾追加文本
o 在光标位置下方新起一行并开始输入文本
O 在光标位置的上方新起一行并开始输入文本
s 删除当前光标位置的字符并开始输入文本
S 删除当前行并开始输入文本
gi 从当前缓冲区上次结束输入模式的地方开始输入文本
gI 在当前行的第一列的位置开始输入文本
值得注意的是这些命令的小写/大写模式,每一个小写命令都有一个与之对应的大写命令。如果你是初学者,不用担心记不住以上整个命令列表,可以从 i 和 a两条命令开始,这两条命令足够在入门阶段使用了,之后再逐渐地掌握更多其他的命令。
退出输入模式的方法
下面列出了一些从输入模式退出到普通模式的方法:
<esc> 退出输入模式进入普通模式
Ctrl-[ 退出输入模式进入普通模式
Ctrl-c 与 Ctrl-[ 和 <esc>功能相同, 但是不检查缩写
我发现 esc键在键盘上太远了,很难够到,所以我在我的机器上将 caps lock 映射成了esc键。 如果你搜索Bill Joy(Vi的作者)的ADM-3A 键盘, 你会发现esc键并不是像现在流行的键盘布局一样在键盘的最左上方,而是在q键的左边,所以我认为将caps lock 映射成esc键是合理的。
另一个Vim用户中常见的习惯是用以下的配置方法在输入模式中把esc映射到jj或者jk。
inoremap jj <esc>
inoremap jk <esc>
重复输入模式
你可以在进入输入模式之前传递一个计数参数. 比如:
10i
如果你输入“hello world!”然后退出输入模式, Vim将重复这段文本10次。这个方法对任意一种进入输入模式的方式都有效(如:10I, 11a, 12o)
在输入模式中删除大块文本
当你输入过程中出现一些输入错误时,一直重复地用backspace来删除的话会非常地繁琐。更为合理的做法是切换到普通模式并使用d来删除错误。或者,你能用以下命令在输入模式下就删除一个或者多个字符:
Ctrl-h 删除一个字符
Ctrl-w 删除一个单词
Ctrl-u 删除一整行
此外,这些快捷键也支持在 命令行模式 和 Ex模式 中使用(命令行模式和Ex模式将会在之后的章节中介绍)
用寄存器进行输入
寄存器就像是内存里的暂存器一样,可供存储和取出文本。在输入模式下,可以使用快捷键Ctrl-r加上寄存器的标识来从任何有标识的寄存器输入文本。有很多标识可供使用,但是在这一章节中你只需要知道以(a-z)命名的寄存器是可以使用的就足够了。
让我们在一个具体的例子中展示寄存器的用法,首先你需要复制一个单词到寄存器a中,这一步可以用以下这条命令来完成:
"ayiw
"a告诉Vim你下一个动作的目标地址是寄存器ayiw复制一个内词(inner word),可以回顾Vim语法章节查看具体语法。
现在寄存器a存放着你刚复制的单词。在输入模式中,使用以下的快捷键来粘贴存放在寄存器a中文本:
Ctrl-r a
Vim中存在很多种类型的寄存器,我会在后面的章节中介绍更多他们的细节。
页面滚动
你知道在输入模式中也是可以进行页面滚动的吗?在输入模式下,如果你使用快捷键Ctrl-x进入Ctrl-x子模式,你可以进行一些额外操作,页面滚动正是其中之一。
Ctrl-x Ctrl-y 向上滚动页面
Ctrl-x Ctrl-e 向下滚动页面
自动补全
Vim在进入Ctrl-x子模式后(和页面滚动一样),有一个自带的自动补全功能。尽管它不如intellisense或者其他的语言服务器协议(LSP)一样好用,但是也算是一个锦上添花的内置功能了。
下面列出了一些适合入门时学习的自动补全命令:
Ctrl-x Ctrl-l 补全一整行
Ctrl-x Ctrl-n 从当前文件中补全文本
Ctrl-x Ctrl-i 从引用(include)的文件中补全文本
Ctrl-x Ctrl-f 补全一个文件名
当你出发自动补全时,Vim会显示一个选项弹窗,可以使用Ctrl-n和Ctrl-p来分别向上和向下浏览选项。
Vim也提供了两条不需要进入Ctrl-x模式就能使用的命令:
Ctrl-n 使用下一个匹配的单词进行补全
Ctrl-p 使用上一个匹配的单词进行补全
通常Vim会关注所有缓冲区(buffer)中的文本作为自动补全的文本来源。如果你打开了一个缓冲区,其中一行是”Chocolate donuts are the best”:
- 当你输入”Choco”然后使用快捷键
Ctrl-x Ctrl-l, Vim会进行匹配并输出这一整行的文本。 - 当你输入”Choco”然后使用快捷键
Ctrl-p,Vim会进行匹配并输出”Chocolate”这个单词。
Vim的自动补全是一个相当大的话题,以上只是冰山一角,想要进一步学习的话可以使用:h ins-completion命令进行查看。
执行普通模式下的命令
你知道Vim可以在输入模式下执行普通模式的命令吗?
在输入模式下, 如果你按下Ctrl-o,你就会进入到insert-normal(输入-普通)子模式。如果你关注一下左下角的模式指示器,通常你将看到-- INSERT -- ,但是按下Ctrl-o后就会变为-- (insert) --。 在这一模式下,你可以执行一条普通模式的命令,比如你可以做以下这些事:
设置居中以及跳转
Ctrl-o zz 居中窗口
Ctrl-o H/M/L 跳转到窗口的顶部/中部/底部
Ctrl-o 'a 跳转到标志'a处
重复文本
Ctrl-o 100ihello 输入 "hello" 100 次
执行终端命令
Ctrl-o !! curl https://google.com 运行curl命令
Ctrl-o !! pwd 运行pwd命令
快速删除
Ctrl-o dtz 从当前位置开始删除文本,直到遇到字母"z"
Ctrl-o D 从当前位置开始删除文本,直到行末
聪明地学习输入模式
如果你和我一样是从其他文本编辑器转到Vim的,你或许也会觉得一直待在输入模式下很有诱惑力,但是我强烈反对你在没有输入文本时,却仍然待在输入模式下。应该养成当你的双手没有在输入时,就退出到普通模式的好习惯。
当你需要进行输入时,先问问自己将要输入的文本是否已经存在。如果存在的话,试着复制或者移动这段文本而不是手动输入它。再问问自己是不是非得进入输入模式,试试能不能尽可能地使用自动补全来进行输入。尽量避免重复输入同一个单词。
第7章 点命令
在编辑文本时,我们应该尽可能地避免重复的动作。在这一章节中,你将会学习如何使用点命令来重放上一个修改操作。点命令是最简单的命令,然而又是减少重复操作最为有用的命令。
用法
正如这个命令的名字一样,你可以通过按下.键来使用点命令。
比如,如果你想将下面文本中的所有”let“替换为”const”:
let one = "1";
let two = "2";
let three = "3";
- 首先,使用
/let来进行匹配。 - 接着,使用
cwconst<esc>来将”let”替换成”const”。 - 第三步,使用
n来找到下一个匹配的位置。 - 最后,使用点命令(
.)来重复之前的操作。 - 持续地使用
n . n .直到每一个匹配的词都被替换。
在这个例子里面,点命令重复的是cwconst<esc>这一串命令,它能够帮你将需要8次输入的命令简化到只需要敲击一次键盘。
什么才算是修改操作?
如果你查看点命令的定义的话(:h .),文档中说点命令会重复上一个修改操作,那么什么才算是一个修改操作呢?
当你使用普通模式下的命令来更新(添加,修改或者删除)当前缓冲区中的内容时,你就是在执行一个修改操作了。其中的例外是使用命令行命令进行的修改(以:开头的命令),这些命令不算作修改操作。
在第一个例子中,你看到的cwconst<esc>就是一个修改操作。现在假设你有以下这么一个句子:
pancake, potatoes, fruit-juice,
我们来删除从这行开始的位置到第一个逗号出现的位置。你可以使用df,来完成这个操作,使用.来重复两次直到你将整个句子删除。
让我们再来试试另一个例子:
pancake, potatoes, fruit-juice,
这一次你只需要删除所有的逗号,不包括逗号前面的词。我们可以使用f,来找到第一个逗号,再使用x来删除光标下的字符。然后使用用.来重复两次,很简单对不对?等等!这样做行不通(只会重复删除光标下的一个字符,而不是删除逗号)!为什么会这样呢?
在Vim里,修改操作是不包括移动(motions)的,因为移动(motions)不会更新缓冲区的内容。当你运行f,x,你实际上是在执行两个独立的操作:f,命令只移动光标,而x更新缓冲区的内容,只有后者算作修改动作。和之前例子中的df,进行一下对比的话,你会发现df,中的f,告诉删除操作d哪里需要删除,是整个删除命令df,的一部分。
让我们想想办法完成这个任务。在你运行f,并执行x来删除第一个逗号后,使用;来继续匹配f的下一个目标(下一个逗号)。之后再使用.来重复修改操作,删除光标下的字符。重复; . ; .直到所有的逗号都被删除。完整的命令即为f,x;.;.。
再来试试下一个例子:
pancake
potatoes
fruit-juice
我们的目标是给每一行的结尾加上逗号。从第一行开始,我们执行命令A,<esc>j来给结尾加上逗号并移动到下一行。现在我们知道了j是不算作修改操作的,只有A,算作修改操作。你可以使用j . j . 来移动并重复修改操作。完整的命令是A,<esc>j。
从你按下输入命令(A)开始到你退出输入模式(
重复多行修改操作
假设你有如下的文本:
let one = "1";
let two = "2";
let three = "3";
const foo = "bar";
let four = "4";
let five = "5";
let six = "6";
let seven = "7";
let eight = "8";
let nine = "9";
你的目标是删除除了含有”foo”那一行以外的所有行。首先,使用d2j删除前三行。之后跳过”foo”这一行,在其下一行使用点命令两次来删除剩下的六行。完整的命令是d2jj..。
这里的修改操作是d2j,2j不是一个移动(motion)操作,而是整个删除命令的一部分。
我们再来看看下一个例子:
zlet zzone = "1";
zlet zztwo = "2";
zlet zzthree = "3";
let four = "4";
我们的目标是删除所有的’z’。从第一行第一个字符开始,首先,在块可视化模式下使用Ctrl-vjj来选中前三行的第一个’z’字母。如果你对块可视化模式不熟悉的话也不用担心,我会在下一章节中进行介绍。在选中前三行的第一个’z’后,使用d来删除它们。接着用w移动到下一个z字母上,使用..重复两次之前选中加删除的动作。完整的命令为Ctrl-vjjdw..。
你删除一列上的三个’z‘的操作(Ctrl-vjjd)被看做一整个修改操作。可视化模式中的选择操作可以用来选中多行,作为修改动作的一部分。
在修改中包含移动操作
让我们来重新回顾一下本章中的第一个例子。这个例子中我们使用了/letcwconst<esc>紧接着n . n .将下面的文本中的’let’都替换成了’const’。
let one = "1";
let two = "2";
let three = "3";
其实还有更快的方法来完成整个操作。当你使用/let搜索后,执行cgnconst<Esc>,然后. . .。
gn是一个移动并选择的动作,它向前搜索和上一个搜索的模式(本例中为/let)匹配的位置,并且 自动对匹配的文本进行可视化模式下的选取。想要对下一个匹配的位置进行替换的话,你不再需要先移动在重复修改操作(n . n .),而是简单地使用. .就能完成。你不需要再进行移动操作了,因为找到下一个匹配的位置并进行选中成为了修改操作的一部分了。
当你在编辑文本时,应该时刻关注像gn命令这种能一下子做好几件事的移动操作。
(译者在这里研究了一会,并做了不少实验,总结规律是:单独的motion(第4章中所说的名词)不算修改操作,而opeartor(动词)+motion(名词)时(请回顾第4章),motion被视为一个完整的修改操作中的一部分。再看一个例子,看看
/命令是如何被包含在一个修改操作中的:
a
b
foo
c
d
foo
e
f
假设你的光标在第一行的a上,执行命令
d/foo<Esc>,Vim会删除a,b。然后.,Vim会删除foo, c, d,再按.,Vim什么也不做,因为后面没有”foo”了。在这个例子中,/foo是一个motion(名词),是Vim语法(动词+名词:operator + motion)的一部分,前面的d则是动词。d/foo<Esc>这条命令的功能是:从当前光标所在位置开始删除,直到遇到”foo”为止。后面的点命令就重复这个功能,第二次按.之所以Vim什么也不做,是因为找不到下一个匹配了,所以这条命令就失效了。
聪明地学习点命令
点命令的强大之处在于使用仅仅1次键盘敲击代替好几次敲击。对于x这种只需一次敲击键盘就能完成的修改操作来说,点命令或许不会带来什么收益。但是如果你的上一个修改操作是像cgnconst<esc>这种复杂命令的话,使用点命令来替代就有非常可观的收益了。
在进行编辑时,思考一下你正将进行的操作是否是可以重复的。举个例子,如果我需要删除接下来的三个单词,是使用d3w更划算,还是dw再使用.两次更划算?之后还会不会再进行删除操作?如果是这样的话,使用dw好几次确实比d3w更加合理,因为dw更加有复用性。在编辑时应该养成“修改操作驱动”的观念。
点命令非常简单但又功能强大,帮助你开始自动化处理简单的任务。在后续的章节中,你将会学习到如何使用Vim的宏命令来自动化处理更多复杂的操作。但是首先,还是让我们来学习一下如何使用寄存器来存取文本吧。
第8章 寄存器
学习Vim中的寄存器就像第一次学习线性代数一样,除非你学习了他们,否则你会觉得自己根本不需要它们。
你可能已经在复制或删除文本并用p或P粘贴它们到别处的时候使用过Vim的寄存器了。但是,你知道Vim总共有10种不同类型的寄存器吗?如果正确地使用Vim寄存器,将帮助您从重复的输入中解放出来。
在这一章节中,我会介绍Vim的所有寄存器类型,以及如何有效地使用它们。
寄存器的10种类型
下面是Vim所拥有的10种寄存器类型:
- 匿名寄存器(
""). - 编号寄存器(
"0-9). - 小删除寄存器 (
"-). - 命名寄存器 (
"a-z). - 只读寄存器 (
":,"., and"%). - Buffer交替文件寄存器 (
"#). - 表达式寄存器 (
"=). - 选取和拖放寄存器(
"*and"+). - 黑洞寄存器 (
"_). - 搜索模式寄存器 (
"/).
寄存器命令
要使用寄存器,您必须先使用命令将内容存储到寄存器,以下是一些存值到寄存器中的操作:
y 复制
c 删除文本并进入输入模式
d 删除文本
其实还有更多的寄存器写入操作(比如s或x),但是上面列出的是最常用的一些。根据经验看来,如果一个操作删除了文本,那么很有可能这个操作将移除的文本存入寄存器中了。
想要从寄存器中取出(粘贴)文本,你可以用以下的命令:
p 在光标位置之后粘贴文本
P 在光标位置之前粘贴文本
p和P都可以接受计数和一个寄存器标志作为参数。比如,想要把最近复制的文本粘贴10次的话可以用10p。想粘贴寄存器”a”中的文本,可以用"ap。想将寄存器“a”中的文本粘贴10次的话,可以使用10"ap。注意,从技术层面讲,命令p实际上表示的是”put”(放置),而不是”paste”(粘贴),使用粘贴只是因为它更符合传统习惯。
从某个特定寄存器中读取文本的通用语法是"x,其中x是这个寄存器的标志。
在输入模式中使用寄存器
在这一章节中你学到的东西在输入模式中也同样适用。想要获取寄存器”a”中的文本,通常可以使用"ap来进行。不过当你在输入模式下时,你需要运行Ctrl-r a。在输入模式下使用寄存器的语法是:
Ctrl-r x
其中x是寄存器标志。既然你现在已经知道如何存储和访问寄存器了,让我们学点更深入的吧。
匿名寄存器("")
想从匿名寄存器中获取文本,可以使用""p。 匿名寄存器默认存储着你最近一次复制,修改或删除的文本。如果再进行另一次复制,修改或删除,Vim会自动替换匿名寄存器中的文本。匿名寄存器和电脑上粘贴板的功能很接近。
默认情况下,p(或者P)是和匿名寄存器相关联的(从现在起我将使用p而不是""p来指代匿名寄存器)。
编号寄存器("0-9)
编号寄存器会自动以升序来进行填充。一共有两种不同的编号寄存器:复制寄存器(0)和其他编号寄存器(1-9)。让我们先来讨论复制寄存器。
复制寄存器 ("0)
如果你使用yy来复制一整行文本,事实上Vim会将文本存放两个寄存器中:
- 匿名寄存器 (
p). - 复制寄存器 (
"0p).
在你又复制其他不同的文本后,Vim会自动替换匿名寄存器和复制寄存器(0)中的内容。其他的任何操作都不会被存放在0号寄存器中。这可以为你提供方便,因为除非你再进行另一次复制,否则你已经复制的内容会一直在寄存器中,无论你进行多少次修改和删除。
比如,如果你:
- 复制一整行 (
yy) - 删除一整行(
dd) - 再删除另一行 (
dd)
复制寄存器中的文本仍然是第一步中复制的文本。
如果你:
- 复制一整行 (
yy) - 删除一整行 (
dd) - 复制另一行 (
yy)
复制寄存器中的内容则是第三步中复制的内容。
还有一个小技巧,在输入模式下,你可以使用Ctrl-r 0快速地粘贴你刚才复制的内容。
编号寄存器 ("1-9)
当你修改或者删除至少一整行的文本时,这部分文本会按时间顺序被存储在1-9号编号寄存器中。(编号越小时间距离越近)
比如,你有以下这些文本:
line three
line two
line one
当你的光标在文本“line three”上时,使用dd来一行一行地删除这些文本。在所有文本都已经删除后,1号寄存器中的内容应该是”line one”(时间上最近的文本), 2号寄存器则包含”line two”(时间上第二近的文本),3号寄存器中则包含”line three”(最早删除的文本)。普通模式下可以使用"1p来获取1号寄存器中的内容。
编号寄存器的编号在使用点命令时会自动增加。比如,如果你的1号编号寄存器("1)中的内容为”line one”, 2号寄存器("2)为”line two”, 三号寄存器("3)”line three”,你可以使用以下的技巧来连续地粘贴他们:
- 使用
"1p来粘贴1号寄存器中的内容。 - 使用
.(点命令)来粘贴2号寄存器("2)中的内容。 - 使用
.(点命令)来粘贴3号寄存器("3)中的内容。
在连续地使用点命令时,Vim会自动的增加编号寄存器的编号。这个技巧对于所有的编号寄存器都适用。如果你从5号寄存器开始("5P), 点命令.会执行"6P,再次使用.则会执行"7P,等等。
小型的删除比如单词删除(dw)或者单词修改(cw)不会被存储在编号寄存器中,它们被存储在小删除寄存器("-)中,我将在接下来的一小节讨论小删除寄存器。
小删除寄存器("-)
不足一行的修改或者删除都不会被存储在0-9号编号寄存器中,而是会被存储在小删除寄存器 ("-)中。
比如:
- 删除一个单词 (
diw) - 删除一行文本 (
dd) - 删除一行文本 (
dd)
"-p 会给你第一步中删除的单词。
另一个例子:
- 删除一个单词(
diw) - 删除一行文本 (
dd) - 删除一个单词 (
diw)
"-p 会给出第三步中删除的单词。类似地, "1p 会给出第二步中删除的一整行文本。不幸的是我们没有办法获取第一步中删除的单词,因为小删除寄存器只能存储一个文本。然而,如果你想保存第一步中删除的文本,你可以使用命名寄存器来完成。
命名寄存器 ("a-z)
命名寄存器是Vim中用法最丰富的寄存器。a-z命名寄存器可以存储复制的,修改的和被删除的文本。不像之前介绍的3种寄存器一样,它们会自动将文本存储到寄存器中,你需要显式地告诉Vim你要使用命名寄存器,你拥有完整的控制权。
为了复制一个单词到寄存器”a”中,你可以使用命令"ayiw。
"a告诉Vim下一个动作(删除/修改/复制)会被存储在寄存器”a”中yiw复制这个单词
为了从寄存器”a”中获取文本,可以使用命令"ap。你可以使用以26个字母命名的寄存器来存储26个不同的文本。
有时你可能会想要往已有内容的命名寄存器中继续添加内容,这种情况下,你可以追加文本而不是全部重来。你可以使用大写版本的命名寄存器来进行文本的追加。比如,假设你的”a”寄存器中已经存有文本”Hello”,如果你想继续添加”world”到寄存器”a”中,你可以先找到文本”world”然后使用"Aiw来进行复制,即可完成追加。
只读寄存器(":, "., "%)
Vim有三个只读寄存器:.,:和%,它们的用法非常简单:
. 存储上一个输入的文本
: 存储上一次执行的命令
% 存储当前文件的文件名
如果你写入”Hello Vim”,之后再运行".p就会打印出文本”Hello Vim”。如果你想要获得当前文件的文件名,可以运行命令"%p。如果你运行命令:s/foo/bar/g,再运行":p的话则会打印出文本”s/foo/bar/g”。
Buffer交替文件寄存器 ("#)
在Vim中,#通常代表交替文件。交替文件指的是你上一个打开的文件,想要插入交替文件的名字的话,可以使用命令"#p。
表达式寄存器 ("=)
Vim有一个表达式寄存器,"=,用于计算表达式的结果。
你可以使用以下命令计算数学表达式1+1的值:
"=1+1<Enter>p
在这里,你在告诉Vim你正在使用表达式寄存器"=,你的表达式是(1+1),你还需要输入p来得到结果。正如之前所提到的,你也可以在输入模式中访问寄存器。想要在输入模式中计算数学表达式的值,你可以使用:
Ctrl-r =1+1
你可以使用@来从任何寄存器中获取表达式并用表达式寄存器计算其值。如果你希望从寄存器”a”中获取文本:
"=@a
之后输入<enter>,再输入p。类似地,想在输入模式中得到寄存器”a”中的值可以使用:
Ctrl-r =@a
表达式是Vim中非常宏大的一个话题,所以我只会在这里介绍一些基础知识,我将会在之后的VimScript章节中进一步讲解更多关于表达式的细节。
选取和拖放寄存器 ("*, "+)
你难道不觉得有些时候你需要从某些外部的程序中复制一些文本并粘贴到Vim中吗,或者反过来操作?有了Vim的选取和拖放寄存器你就能办到。Vim有两个选取寄存器:quotestar ("*) 和 quoteplus ("+)。你可以用它们来访问从外部程序中复制的文本。
如果你在运行一个外部程序(比如Chrome浏览器),然后你使用Ctrl-c(或者Cmd-c,取决于你的操作系统)复制了一部分文本,通常你是没有办法在Vim里使用p来粘贴这部分文本的。但是,Vim的两个寄存器"+和"*都是和你系统的粘贴板相连接的,所以你可以使用"+p和"*p来粘贴这些文本。反过来,如果你使用"+yiw或者"*yiw在Vim中复制了一些文本,你可以使用Ctrl-v(或者Cmd-v)。值得注意的是这个方法只在你的Vim开启了+clipboard选项时才有用,可以在命令行中运行vim --version查看这一选项。如果你看见-clipboard的话,则需要安装一下支持Vim粘贴板的配置。
你也许会想如果"*和"+能办到的事完全相同,那为什么Vim需要两个不同的寄存器呢?一些机器使用的是X11窗口系统,这一系统有3个类型的选项:首选,次选和粘贴板。如果你的机器使用的是X11的话,Vim使用的是quotestar ("*)寄存器作为X11的首选选项,并使用 quoteplus ("+)作为粘贴板选项。这只在你的Vim配置里开启了xterm_clipboard 选项时才有效(vim --version中的+xterm_clipboard)。如果你的的Vim配置中没有 xterm_clipboard也不是什么大问题。这只是意味着quotestar 和quoteplus两个寄存器是可以互相替代的。
我发觉使用=*p或者=+p的话比较麻烦,为了使Vim仅使用p就能粘贴从外部程序复制的文本,你可以在你的vimrc配置文件中加入下面一行:
set clipboard=unnamed
现在当我从外部程序中复制文本时,我可以使用匿名寄存器p来进行粘贴。我也可以在Vim中复制文本后在外部程序中使用Ctrl-v来粘贴。如果你的Vim开启了 +xterm_clipboard设置,你或许会想同时也使用unnamed和unnamedplus的粘贴板选项。
黑洞寄存器 ("_)
你每次删除或修改文本的时候,这部分文本都会自动保存在Vim的寄存器中。有些时候你并不希望把什么东西都往寄存器里存,这该怎么办到呢?
你可以使用黑洞寄存器("_)。想要删除一行并且不将其存储在任何寄存器中时,可以使用"_dd命令.
它是和 /dev/null 类似的寄存器。
搜索模式寄存器 ("/)
为了粘贴你的上一个搜索询问(/ 或 ?),你可以使用搜索模式寄存器("/)。使用命令 "/p就能粘贴上一个搜索的条目。
查看所有的寄存器
你可以使用:register命令来查看你的所有寄存器。如果你只想查看”a”,”1”和”-“寄存器的内容的话则可以使用命令:register a 1 -。
有一个Vim的插件叫做 vim-peekaboo ,可以让你查看到寄存器的内容,在普通模式下输入"或@ 即可,或者在输入模式中输入Ctrl-r。我发现这个插件相当的有用,因为大多数时候我是记不住我的寄存器中的内容的。值得一试!
执行寄存器
命名寄存器不只可以用来存放文本,你还可以借助@来执行宏命令。我会在下一章节中介绍宏命令。
注意,因为宏命令时存储在Vim寄存器中的,使用宏时可能会覆盖存储的内容。如果你将文本”Hello Vim”存放在寄存器”a”中,并且之后你在同一个寄存器里记录了一个宏命令 (qa{macro-commands}q),那么这个宏命令将会覆盖之前存储的文本”Hello Vim”(你可以使用@a来执行寄存器中存储的宏命令)。
清除寄存器
从技术上来说,我们没有必要来清除任何寄存器,因为你下一个使用来存储文本的寄存器会自动覆盖该寄存器中之前的内容。然而,你可以通过记录一个空的宏命令来快速地清除任何命名寄存器。比如,如果你运行qaq,Vim就会在寄存器”a”中记录一个空的宏命令。
还有一种方法就是运行命令:call setreg('a','hello register a'),其中’a’代表的就是寄存器”a”。而”hello register a”就是你想存储的内容。
还有一种清除寄存器的方法就是使用表达式:let @a = ''来将寄存器”a 的值设为空的字符串。
获取寄存器中的内容
你可以使用:put命令来粘贴任何寄存器的内容。比如,如果你运行命令:put a,Vim就会打印出寄存器”a”的内容,这和"ap非常像,唯一的区别在于在普通模式下命令p在当前光标位置之后打印寄存器的内容,而:put新起一行来打印寄存器的内容。
因为:put是一个命令行命令,您可以传一个地址给它。:10put a将会在当前光标下数10行,然后插入新行,内容为寄存器a中的内容。
一个很酷的技巧是将黑洞寄存器("_)传给:put命令。因为黑洞寄存器不保存任何值,:put _命令将插入一个新的空白行。您可将这个与全局命令联合起来,插入多个空行。比如,要在所有以文本”end”结尾的行下插入空行,使用:g/end/put _。在后面您将了解关于全局命令的知识。
聪明地学习寄存器
恭喜你成功地坚持到了最后!这一章有非常多的内容需要消化。如果你感觉被新的知识淹没,你要知道你并不孤单,当我最初开始学习Vim寄存器时也有这种感觉。
我并不认为你必须现在就记得所有的知识点。为了提高我们的生产效率,你可以从使用以下三类寄存器开始:
- 匿名寄存器(
""). - 命名寄存器 (
"a-z). - 编号寄存器 (
"0-9).
既然匿名寄存器是默认和p或P,你只需要学习两个寄存器:命名寄存器和编号寄存器。之后如果你需要用到其他的寄存器时你再逐渐地学习其他寄存器的用法,不用急,慢慢来。
普通人的短期记忆都是有极限的,大概每次只能记住5-7个信息。这就是为什么在我的日常编辑中,我只用3到7个命名寄存器的原因,我没有办法记住整整26个寄存器的内容。我通常从寄存器”a”开始用,之后用寄存器”b”,以字母表升序的顺序来使用。尝试一下各种方法,看看哪种最适合你。
Vim寄存器非常强大,合理使用的话能够避免你输入数不清的重复文本。但是现在,是时候学习一下宏命令了。
第9章 宏命令
在编辑文件的时候,你会发现有时候你在反复地做一些相同的动作。如果你仅做一次,并在需要的时候调用这些动作岂不是会更好吗。通过 Vim 的宏命令,你可以将一些动作记录到 Vim 寄存器。
在本章中,你将会学习到如何通过宏命令自动完成一些普通的任务(另外,看你的文件在自动编辑是一件很酷的事情)。
基本宏命令
宏命令的基本语法如下:
qa 开始记录动作到寄存器 a
q (while recording) 停止记录
你可以使用小写字母 (a-z)去存储宏命令。并通过如下的命令去调用:
@a Execute macro from register a
@@ Execute the last executed macros
假设你有如下的文本,你打算将每一行中的所有字母都变为大写。
hello
vim
macros
are
awesome
将你的光标移动到 “hello” 栏的行首,并执行:
qa0gU$jq
上面命令的分解如下:
qa开始记录一个宏定义并存储在 a 寄存器。0移动到行首。gU$将从光标到行尾的字母变为大写。j移动到下一行。q停止记录。
调用 @a 去执行该宏命令。就像其他的宏命令一样,你也可以为该命令加一个计数。例如,你可以通过 3@a 去执行 a 命令3次。你也可以执行 3@@ 去执行上一次执行过的宏命令3次。
安全保护
在执行遇到错误的时候,宏命令会自动停止。假如你有如下文本:
a. chocolate donut
b. mochi donut
c. powdered sugar donut
d. plain donut
你想将每一行的第一个词变为大写,你可以使用如下的宏命令:
qa0W~jq
上面命令的分解如下:
qa开始记录一个宏定义并存储在 a 寄存器。0移动到行首。W移动到下一个单词。~将光标选中的单词变为大写。j移动到下一行。q停止记录。
我喜欢对宏命令进行超过所需次数的调用,所以我通常使用 99@a 命令去执行该宏命令99次。使用该命令,Vim并不会真正执行这个宏99次,当 Vim 到达最后一行执行j时,它会发现无法再向下了,然后会抛出一个错误,并终止宏命令的执行。
实际上,遇到错误自动停止运行是一个很好的特性。否则,Vim 会继续执行该命令99次,尽管它已经执行到最后一行了。
命令行执行宏
在正常模式执行 @a 并不是宏命令调用的唯一方式。你也可以在命令行执行 :normal @a 。:normal 会将任何用户添加的参数作为命令去执行。例如添加 @a,和在 normal mode 执行 @a 的效果是一样的。
:normal 命令也支持范围参数。你可以在选择的范围内去执行宏命令。如果你只想在第二行和第三行执行宏命令,你可以执行 :2,3 normal @a。
在多个文件中执行宏命令
假如你有多个 .txt 文件,每一个文件包含不同的内容。并且你只想将包含有 “donut” 单词的行的第一个单词变为大写。假设,您的寄存器a中存储的内容是0W~j(就是前面例子中用到的宏命令),那么,您该如何快速完成这个操作呢?
第一个文件:
## savory.txt
a. cheddar jalapeno donut
b. mac n cheese donut
c. fried dumpling
第二个文件:
## sweet.txt
a. chocolate donut
b. chocolate pancake
c. powdered sugar donut
第三个文件:
## plain.txt
a. wheat bread
b. plain donut
你可以这么做:
:args *.txt查找当前目录下的所有.txt文件。:argdo g/donut/normal @a在:args中包含的每一个文件里执行一个全局命令g/donut/normal @a。:argdo update在:args中包含的每一个文件里执行update命令,保存修改后的内容。
也许你对全局命令 :g/donut/normal @a 不是很了解,该命令会执行 /donut/搜索命令,然后在所有匹配的行中执行normal @a 命令。我会在后面的章节中介绍全局命令。
递归执行宏命令
你可以递归地执行宏命令,通过在记录宏命令时调用相同的宏寄存器来实现。假如你有如下文本,你希望改变第一个单词的大小写:
a. chocolate donut
b. mochi donut
c. powdered sugar donut
d. plain donut
如下命令会递归地执行:
qaqqa0W~j@aq
上面命令的分解如下:
qaq记录一个空白的宏命令到 “a” 。把宏命令记录在一个空白的命令中是必须的,因为你不会想将该命令包含有任何其他的东西。qa开始录入宏命令到寄存器 “a”。0移动到行首。W移动到下一个单词。~改变光标选中的单词的大小写。j移动到下一行。@a执行宏命令 “a”。当你记录该宏命令时,@a应该是空白的,因为你刚刚调用了qaq。q停止记录。
现在,让我们调用 @a 来查看 Vim 如何递归的调用该宏命令。
宏命令是如何知道何时停止呢?当宏执行到最后一行并尝试 j 命令时,发现已经没有下一行了,就会停止执行。
增添一个已知宏
如果你想在一个已经录制好的宏定义中添加更多的操作,与其重新录入它,不如选择修改它。在寄存器一章中,你学习了如何使用一个已知寄存器的大写字母来想该寄存器中添加内容。同样的,为了在寄存器”a”中添加更多的操作,你也可以使用大写字母”A”。
假设寄存器a中已经存储了这个宏命令:qa0W~q(该宏命令将某行的第二个词组的头一个字母执行改变大小写操作),假设你想在这个基础上添加一些操作命令序列,使得每一行末尾添加一个句点,运行:
qAA.<esc>q
分解如下:
qA开始在寄存器 “A” 中记录宏命令。A.<esc>在行的末尾加上一个句点(这里的A是进入插入模式,不要和宏A搞混淆),然后退出插入模式。q停止记录宏命令。
现在,当你执行@a时,它不仅将第二个词组的首字母转变大小写,同时还在行尾添加一个句点。
修改一个已知宏
如果想在一个宏的中间添加新的操作该怎么办呢?
假设您在寄存器a中已经存有一个宏命令0W~A.<Esc>,即改变首字母大小写,并在行尾添加句号。如果您想在改变首字母大小写和行尾添加句号之间,在单词”dount”前面加入”deep fried”。(因为唯一比甜甜圈好的东西就是炸甜甜圈)。
我会重新使用上一节使用过的文本:
a. chocolate donut
b. mochi donut
c. powdered sugar donut
d. plain donut
首先,让我们通过 :put a 调用一个已经录制好的宏命令(假设你上一节中保存在寄存器a中的宏命令还在):
0W~A.^[
^[ 是什么意思呢?不记得了吗,你之前执行过 0W~A.<esc>。 ^[ 是 Vim 的 内部指令,表示 <esc>。通过这些指定的特殊键值组合,Vim 知道这些是内部代码的一些替代。一些常见的内部指令具有类似的替代,例如 <esc>,<backspace>,<enter>。还有一些其他的键值组合,但这不是本章的内容。
回到宏命令,在改变大小写之后的键后面(~),让我们添加($)来移动光标到行末,回退一个单词(b),进入插入模式(i),输入”deep fried “ (别忽略”fried “后面的这个空格),之后退出插入模式(<esc>)。
完整的命令如下:
0W~$bideep fried <esc>A.^[
这里有一个问题,Vim 不能理解 <esc>。您不能依葫芦画瓢输入”
0W~$bideep fried ^[A.^[
为了在寄存器“a”中添加修改后的指令,你可以通过在一个已知命名寄存器中添加一个新条目的方式来实现。在一行的行首,执行 "ay$,使用寄存器 “a”来存储复制的文本。
现在,但你执行 @a 时,你的宏命令会自动改变第一个单词的大小写,在”donut”前面添加”deep fried “,之后在行末添加“.”。
另一个修改宏命令的方式是通过命令行表达式。执行 :let @a=",之后执行 Ctrl-r Ctrl-r a,这会将寄存器“a”的命令逐字打印出来。最后,别忘记在闭合的引号(")。如果你希望在编辑命令行表达式时插入内部码来使用特定的字符,你可以使用 Ctrl-v。
拷贝宏
你可以很轻松的将一个寄存器的内容拷贝到另一个寄存器。例如,你可以使用 :let @z = @a 将寄存器”a” 中的命令拷贝到寄存器”z”。 @a 表示寄存器“a”中存储的内容,你现在执行 @z,将会执行和 @a 一样的指令。
我发现对常用的宏命令创建冗余是很有用的。在我的工作流程中,我通常在前7个字母(a-g)上创建宏命令,并且我经常不加思索地把它们替换了。因此,如果我将很有用的宏命令移动到了字母表的末尾,就不用担心我在无意间把他们替换了。
串行宏和并行宏
Vim 可以连续和同时运行宏命令,假设你有如下的文本:
import { FUNC1 } from "library1";
import { FUNC2 } from "library2";
import { FUNC3 } from "library3";
import { FUNC4 } from "library4";
import { FUNC5 } from "library5";
假如你希望把所有的 “FUNC” 字符变为小写,那么宏命令为如下:
qa0f{gui{jq
分解如下:
qa开始记录宏命令到 “a” 寄存器。0移动到第一行。f{查找第一个 “{” 字符。gui{把括号内的文本(i{)变为小写(gu)。j移动到下一行。q停止记录宏命令。
现在,执行 99@a 在剩余的行修改。然而,假如在你的文本里有如下 import 语句会怎么样呢?
import { FUNC1 } from "library1";
import { FUNC2 } from "library2";
import { FUNC3 } from "library3";
import foo from "bar";
import { FUNC4 } from "library4";
import { FUNC5 } from "library5";
执行 99@a,会只在前三行执行。而最后两行不会被执行,因为在执行第四行(包含“foo”)时f{命令会遇到错误而停止,当宏串行执行时就会发生这样的情况。当然,你仍然可以移动到包含(“FUNC4”)的一行,并重新调用该命令。但是假如你希望仅调用一次命令就完成所有操作呢?
你可以并行地执行宏命令。
如本章前面所说,可以使用 :normal 去执行宏命令,(例如: :3,5 normal @a 会在 3-5行执行 a 寄存器中的宏命令)。如果执行 :1,$ normal @a,会在所有除了包含有 “foo” 的行执行,而且它不会出错。
尽管本质上来说,Vim 并不是在并行地执行宏命令,但表面上看,它是并行运行的。 Vim 会独立地在从第一行开始(1,$)每一行执行 @a 。由于 Vim 独立地在每一行执行命令,每一行都不会知道有一行(包含“foo”)会遇到执行错误。
聪明地学习宏命令
你在编辑器里做的很多事都是重复的。为了更好地编辑文件,请乐于发现这些重复性的行为。执行宏命令或者点命令,而不是做相同的动作两次。几乎所有你在 Vim 所作的事情都可以变为宏命令。
刚开始的时候,我发现宏命令时很棘手的,但是请不要放弃。有了足够的练习,你可以找到这种文本自动编辑的快乐。
使用某种助记符去帮助你记住宏命令是很有帮助的。如果你有一个创建函数(function)的宏命令,你可以使用 “f” 寄存器去录制它(qf)。如果你有一个宏命令去操作数字,那么使用寄存器 “n” 去记住它是很好的(qn)。用你想执行的操作时想起的第一个字符给你的宏命令命名。另外,我发现 “q” 是一个很好的宏命令默认寄存器,因为执行 qq 去调用宏命令是很快速而简单的。最后,我喜欢按照字母表的顺序去添加我的宏命令,例如从 qa 到 qb 再到 qc。
去寻找最适合你的方法吧。
第10章 撤销
所有人都会犯各种各样的输入错误。因此对于任何一个现代的软件来说,撤销都是一个很基本的功能。 Vim 的撤销系统不仅支持撤销和取消撤销任何修改,而且支持存取不同的文本形态,让你能控制你输入的所有文本。在本章中,你将会学会如何执行撤销和 取消撤销文本,浏览撤销分支,反复撤销, 以及浏览改动时间线。
撤销(undo),重做和行撤销(UNDO)
对于一个基本的 undo 操作,你可以执行 u 或者 :undo。
假设你有如下文本(注意”one”下面有一个空行):
one
然后添加另一个文本:
one
two
如果你执行 u,Vim 会删除 “two”。
Vim 是如何知道应该恢复多少修改呢? 答案是,Vim每次仅恢复一次修改,这有点类似于点命令的操作(和 点命令不同之处在于,命令行命令也会被算作一次修改)。
要取消上一次的撤销,可以执行 Ctrl-r 或者 :redo。例如上面的例子中,当你执行撤销来删除 “two” 以后,你可以执行 Ctrl-r 来恢复被删除掉的文本。
Vim 也有另一个命令 U 可以实现 行撤销 (UNDO) 的功能,执行这个命令会撤销所有最新的修改。
那么,U 和 u 的区别是什么呢?首先,U 会删除 最近修改的行中所有的 的修改,而 u 一次仅删除一次修改。 其次,执行u 不会被算作一次修改操作,而执行 U 则会被算作一次修改。
让我们会的之前的例子:
one
two
修改第二行的内容为 “three” (ciwthree<esc>):
one
three
再次修改第二行的例子为 “four” (ciwfour<esc>):
one
four
此时,如果你按下 u,你会看到 “three”。如果你再次按下 u,你会看到 “two”。然而,在第二行仍为 “four” 的时候,如果你按下 U,你会看到
one
执行 U 会跳过中间所有修改,直接恢复到文件最初的状态(第二行为空)。另外,由于 UNO 实际上是执行了一个新的修改,因此你可以 UNDO 执行过的 UNDO。 执行 U 后 再次执行 U 会撤销 自己。假如你连续执行 U,那么你将看到第二行的文本不停地出现和消失。
就我个人而言,我几乎不会使用 U,因为很难记住文本最初的样子。(我几乎不使用它)
Vim 可以通过变量 undolevels 来选择最多可执行 undo 的次数。你可以通过 :echo &undolevels 来查看当前的配置。我一般设置为 1000。如果你也想设置为 1000 的话,你可以执行 :set undolevels=1000。不用担心,你可以设置它为任何一个你想设置的值。
断点插入操作
在上文中我提到,u 每次恢复一个修改,类似于点命令。在每次进入 插入模式和退出插入模式之间的任何修改都被定义为一次修改。
如果你执行 ione two three<esc> 之后,按下 u,Vim 会同时删除 “one two three”,因为这是一笔修改。如果你每次只输入较短的文本,那这是可接受的;可假设你在一次插入模式中输入了大量的文本,而后退出了插入模式,可很快你意识到这中间有部分错误。此时,如果你按下 u,你会丢失上一次输入的所有内容。 因此,假设你按下 u 只删除你上一次输入的一部分文本岂不是会更好。
幸运的是,你可以拆分它。当你在插入模式时,按下 Ctrl-G u 会生成一个断点。例如,如果你执行 ione <Ctrl-G u>two <Ctrl-G u>three<esc>,之后你按下u,你仅会失去文本 “three”,再次执行 u,会删除 “two”。当你想要输入一长段内容时,应该有选择性地执行断点插入操作。在每一句话的末尾,两个段落的中间,或者每一行代码结束时插入断点是一个很好的选择,这可以帮助你快速从错误中恢复出来。
在插入模式中,执行删除操作时插入断点也非常有用。例如通过 Ctrl-W 删除光标前的单词时,以及 Ctrl-U删除光标前的所有文本时。一个朋友建议我使用如下的映射:
inoremap <c-u> <c-g>u<c-u>
inoremap <c-w> <c-g>u<c-w>
通过上述命令,你可以很轻松地恢复被删除的文本。
撤销树
Vim 将每一次修改存储在一个撤销树中。你打开一个空白文件,然后添加一段新文本:
one
再插入一段新文本:
one
two
undo一次:
one
插入一段不同的话:
one
three
再次 undo
one
再次插入另一段话:
one
four
现在如果你执行 undo,您将丢失刚刚添加的文本 “four” :
one
如果你再次执行 undo 操作:
文本 “one” 也会丢失。对于大部分编辑器来说,找回文本 “two” 和 “three” 都是不可能的事情,但是对于 Vim 来说却不是这样。执行 g+,你会得到:
one
再次执行 g+ ,你将会看到一位老朋友:
one
two
让我们继续执行 g+:
one
three
再一次执行 g+ :
one
four
在 Vim 中,你每一次执行 u 去做一次修改时,Vim都会通过创建一个”撤销分支”来保存之前的文本内容。在本例中,你输入”two”后, 执行 u,然后输入”three”,你就创建了一个叶子分支,保存了含有”two”的文本状态。此时,撤销树已经包含了至少两个叶子节点,主节点包含文本”three”(最新),而另一undo分支节点包含文本“two”。假如你执行了另一次撤销操作并且输入了”four”,那么此时会生成三个节点,一个主节点包含文本”four”, 以及另外两个节点分别存储了”three”和”two”。
为了在几个不同的节点状态间进行切换,你可以执行 g+ 去获取一个较新的状态,以及执行 g- 去获取一个教旧的状态。 u, Ctrl-R, g+, 和 g- 之间的区别是,u and Ctrl-R 只可以在 main 节点之间进行切换,而g+ 和 g- 可以在 所有 节点之间进行切换。
Undo 树并不可以很轻松地可视化。我发现一个插件 vim-mundo 对于理解 undo 树很有帮助。花点时间去与它玩耍吧。
保存撤销记录
当你通过 Vim 打开一个文件,并且立即按下 u,Vim 很可能会显示 “Already at oldest change” 的警告。
要想从最近的一次编辑工作中(在vim关闭文件再打开,算做一次新的编辑工作),在撤销历史中回滚,可以通过 :wundo命令使Vim 保存一份你的 undo 历史记录。
创建一个文件 mynumbers.txt. 输入:
one
插入另一行文件 (确保你要么退出并重新进入插入模式,要么创建了断点):
one
two
插入新的一行:
one
two
three
现在,创建你的撤销记录文件。 语法为 :wundo myundofile。 如果你需要覆盖一个已存在的文件,在 wundo 之后添加 !.
:wundo! mynumbers.undo
退出 Vim。
此时,在目录下,应该有mynumbers.txt 和 mynumbers.undo 两个文件。再次打开 mynumbers.txt 文件并且按下 u,这是没有响应的。因为自打开文件后,你没有执行任何的修改。现在,通过执行 :rundo 来加载 undo 历史。
:rundo mynumbers.undo
此时,如果你按下 u,Vim 会删除 “three”。再次按下 u可以删除 “two”。这就好像你从来没有关闭过 Vim 一样。
如果你想要自动加载 undo 历史文件,你可以通过在你的 .vimrc 文件中添加如下代码:
set undodir=~/.vim/undo_dir
set undofile
我认为将所有的 undo 文件集中保存在一个文件夹中最好,例如在 ~/.vim 目录下。 undo_dir 是随意的。 set undofile 告诉 Vim 打开 undofile 这个特性,因为该特性默认是关闭的。现在,无论你何时保存,Vim 都会自动创建和保存撤销的历史记录(在使用undo_dir目录前,请确保你已经创建了它)。
时间旅行
是谁说时间旅行不存在。 Vim 可以通过 :earlier 命令将文本恢复为之前的状态。
假如有如下文本:
one
之后你输入了另一行:
one
two
如果你输入 “two” 的时间少于10秒,那么你可以通过如下命令恢复到 “two” 还没被输入前的状态:
:earlier 10s
你可以使用 :undolist 去查看之前所做的修改。 :earlier 可以加上分钟 (m), 小时 (h), and 天 (d) 作为参数。
:earlier 10s 恢复到10秒前的状态
:earlier 10m 恢复到10分钟前的状态
:earlier 10h 恢复到10小时前的状态
:earlier 10d 恢复到10天前的状态
另外,它同样接受一个计数作为参数,告诉vim恢复到老状态的次数。比如,如果运行:earlier 2,Vim将恢复到2次修改前的状态。功能类似于执行g-两次。同样,你可以运行:earlier 10f命令告诉vim恢复到10次保存前的状态。
这些参数同样作用于:earlier命令的对应版本::later。
:later 10s 恢复到10秒后的状态
:later 10m 恢复到10分钟后的状
:later 10h 恢复到10小时后的状
:later 10d 恢复到10天后的状态
:later 10 恢复到新状态10次
:later 10f 恢复到10次保存后的状态
聪明地学习撤销操作
u 和 Ctrl-R 是两个不可缺少的 Vim 参数。请先学会它们。在我的工作流中,我并不使用 UNDO,然而我认为承认它存在是很好的。下一步,学会如何使用:earlier 和 :later,以及时间参数。在这之后,请花些时间理解 undo 树。 插件 vim-mundo 对我的帮助很大。单独输入本章中展示的文本,并且查看撤销树的每一次改变。一旦你掌握它,你看待撤销系统的眼光一定不同。
在本章之前,你学习了如何在项目内查找任何文本,配合撤销,你可以在时间维度上查找任何一个文本。你现在可以通过位置和写入时间找到任何一个你想找的文本。你已经对 Vim 无所不能了。
第11章 可视模式
高亮显示文本块并对其进行更改,是很多文本编辑器中的常见功能。 Vim也可以使用可视模式实现这一功能。在本章中,您将学习如何使用可视模式来有效地处理文本块。
三种可视模式
Vim有三种可视模式,分别是:
v 逐字符可视模式
V 逐行可视模式
Ctrl-v 逐块可视模式
如果您有下列文字:
one
two
three
逐字符可视模式用于选择单个字符。在第一行的第一个字符上按v。然后使用j跳转至下一行。它高亮显示从”one”到光标位置的所有文本。现在,如果您按gU,Vim将高亮显示的字符转为大写。
逐行可视模式适用于整行。按V并观看Vim选择光标的所在行。就像逐字符可视模式一样,如果您运行gU,Vim将高亮显示的字符转为大写。
逐块可视模式适用于行和列。与其他两种模式相比,它为您提供了更大的移动自由度。按Ctrl-V,Vim像逐字符可视模式一样高亮显示光标下的字符,但向下移动时,除非光标已经在行尾,否则不会高亮显示光标上方的整行,它跳转至下一行时高亮显示尽可能少的字符。尝试用h/j/k/l移动,并观察光标的移动。
在Vim窗口的左下方,您会看到显示-- VISUAL --,-- VISUAL LINE --或-- VISUAL BLOCK --以提示您所处的可视模式。
当您处于可视模式时,可以通过按v,V或Ctrl-V键切换到另一种可视模式。例如,如果您处于逐行可视模式,并且想要切换为逐块可视模式,请运行Ctrl-V。试试吧!
有三种退出可视模式的方法:esc,Ctrl-C和与当前可视模式相同的键。后者的意思是,如果您当前处于逐行可视模式(V),则可以通过再次按V退出它。如果您处于字符可视模式,则可以通过按v退出它。如果您处于逐块可视模式,请按Ctrl-V。
实际上,还有另一种进入可视模式的方式:
gv 转到上一个可视模式
它将在与上次相同的高亮显示的文本块上启动相同的可视模式。
可视模式导航
在可视模式下,您可以使用Vim动作(motion)扩展高亮显示的文本块。
让我们使用之前使用的相同文本:
one
two
three
这次让我们从”two”行开始。按v进入字符可视模式(这里的方括号[]表示高亮显示的字符):
one
[t]wo
three
按j,Vim将高亮显示从”two”行到”three”行的第一个字符的所有文本。
one
[two
t]hree
假设您刚刚意识到还需要高亮显示”one”行,因此按k。令您沮丧的是,它现在排除了”three”高亮。
one
[t]wo
three
有没有一种方法可以自由地扩展视觉选择范围,以向您想要的任何方向发展?
答案是肯定的。让我们先恢复光标到高亮显示”two”和”three”行的位置。
one
[two
t]hree <-- 光标
高亮区域跟随光标移动。如果要将其向上扩展到行”one”,则需要将光标移动到”two”,现在您的光标在”three”行上。这时可以用o或O切换光标位置。
one
[two <-- 光标
t]hree
现在,当您按k时,它不再缩小选择,而是向上扩展。
[one
two
t]hree
在可视模式中使用o或O,光标会在高亮选择区域的开头和结尾跳转,以便与您扩展高亮区域。
可视模式语法
可视模式与普通模式使用相同的操作符(operations)。
例如,如果您有以下文字,然后您想在可视模式中删除前两行:
one
two
three
用逐行可视模式(V)高亮显示”one”和”two”行:
[one
two]
three
按下d键将删除选择,类似于普通模式。请注意,与普通模式的语法规则有所不同,动词+名词不适用可视模式。虽然存在相同的动词(d),但在可视模式下没有名词。可视模式下的语法规则是名词+动词(反过来了),其中名词是高亮显示的文本。首先选择文本块,然后进行操作。
在普通模式下,有一些命令不需要名词(motion),例如x删除光标下方的单个字符,还有r替换光标下方的字符(rx将当前光标下的字符替换为x)。在可视模式下,这些命令现在将应用于整个高亮显示的文本,而不是单个字符。回到高亮显示的文本:
[one
two]
three
运行x会删除所有高亮显示的文本。
您可以使用此行为在markdown文本中快速创建标题。假设您需要快速下面的文本转换为一级markdown标题(“===”):
Chapter One
首先,您使用yy复制文本,然后使用p粘贴文本:
Chapter One
Chapter One
现在转到第二行,以逐行可视模式选择它:
Chapter One
[Chapter One]
在markdown中,您可以通过在文本下方添加一系列=来创建标题,因此您可以通过运行r=来替换整个高亮显示的文本:
Chapter One
===========
要了解有关可视模式下的运算符的更多信息,请查看:h visual-operators。
可视模式和Ex命令
您可以有选择地在高亮显示的文本块上应用Ex命令。如果您具有以下表达式,并想将前两行的”const”替换为”let”:
const one = "one";
const two = "two";
const three = "three";
用 任意 可视模式高亮显示前两行,然后运行替换命令:s/const/let/g:
let one = "one";
let two = "two";
const three = "three";
请注意,我说过您可以使用 任何 可视模式执行此操作。您不必高亮显示整个行即可在该行上运行Ex命令。只要您在每行上至少选择一个字符,就会应用Ex命令。
跨多行编辑
您可以使用逐块可视模式在Vim中跨多行编辑文本。如果需要在每行末尾添加分号:
const one = "one"
const two = "two"
const three = "three"
将光标放在第一行上:
- 进入逐块可视模式,并向下两行(
Ctrl-V jj)。 - 高亮显示到行尾(
$)。 - 按(
A) ,然后键入”;”。 - 退出可视模式(
esc)。
您应该看到在每一行后面附加的 “;”。666! 有两种方法可以从逐块可视模式进入输入模式:可以使用A在光标后输入文本,也可以使用I在光标前输入文本。请勿将它们与普通模式下的A和I混淆。(普通模式中,A表示在行尾添加内容,I表示在行尾非空字符前插入内容)。
另外,您也可以使用:normal命令在多行添加内容:
-高亮显示所有3行(vjj)。
-输入:normal! A;。
记住,:normal命令执行普通模式命令。您可以指示它运行A;在该行的末尾添加文本”;”。
递增数字
Vim有Ctrl-X和Ctrl-A命令来减少和增加数字。与可视模式一起使用时,可以跨多行递增数字。
如果您具有以下HTML元素:
<div id="app-1"></div>
<div id="app-1"></div>
<div id="app-1"></div>
<div id="app-1"></div>
<div id="app-1"></div>
有多个具有相同名称的id是一个不好的做法,因此让我们对其进行递增以使其唯一:
- 将光标移动到 第二行的 “1”。
- 启动逐块可视模式,并向下移动3行(
Ctrl-V 3j)。这高亮显示剩余的”1”,现在除了第一行,所有的”1”应该已经高亮。 - 运行
g Ctrl-A。
您应该看到以下结果:
<div id="app-1"></div>
<div id="app-2"></div>
<div id="app-3"></div>
<div id="app-4"></div>
<div id="app-5"></div>
g Ctrl-A在多行上递增数字。 Ctrl-X/Ctrl-A也可以增加字母。如果您运行:
:set nrformats+=alpha
nrformats选项指示Vim将哪个基数视为Ctrl-A和Ctrl-X递增和递减的“数字”。通过添加alpha,现在将字母字符视为数字。如果您具有以下HTML元素:
<div id="app-a"></div>
<div id="app-a"></div>
<div id="app-a"></div>
<div id="app-a"></div>
<div id="app-a"></div>
将光标放在第二个”app-a”上。使用与上述相同的技术(Ctrl-V 3j 然后 g Ctrl-A)增加ID。
<div id="app-a"></div>
<div id="app-b"></div>
<div id="app-c"></div>
<div id="app-d"></div>
<div id="app-e"></div>
选择最后一个可视模式区域
前面章节中我提到了gv可以快速高亮显示上一个可视模式选择的内容。您还可以使用以下两个特殊标记转到最后一个可视模式的开始和结束位置:
'< 转到上一个可视模式高亮显示的第一个位置(行)(译者注,英文原版中'<'前面的符号是`,但这应该是一个错误,应该是单引号')
'> 转到上一个可视模式高亮显示的最后位置(行)
之前,我提到过您可以在高亮显示的文本上有选择地执行Ex命令,例如::s/const/let/g。当您这样做时,您应该看到以下内容:
:'<,'>s/const/let/g
您实际上是在使用('<, '>) 标记作为范围来执行 s/const/let/g命令。这太有趣了!
您随时可以随时编辑这些标记。比如,如果您需要从高亮显示的文本的开头到文件的末尾进行替换,则只需将命令行更改为:
:'<,$s/const/let/g
从插入模式进入可视模式
您也可以从插入模式进入可视模式。在插入模式下进入字符可视模式:
Ctrl-O v
回想一下,在插入模式下运行Ctrl-O可以使您执行普通模式命令。在普通模式命令挂起模式下,运行v进入逐字可视模式。请注意,在屏幕的左下方,它显示为--(insert) VISUAL--。该技巧适用于任何可视模式运算符:v,V,和Ctrl-V。
选择模式
Vim具有类似于可视模式的模式,称为选择模式。与可视模式一样,它也具有三种不同的模式:
gh 逐字符选择模式
gH 逐行选择模式
gCtrl-h 逐块选择模式
选择模式比Vim的可视模式更接近常规编辑器的文本高亮显示行为。
在常规编辑器中,高亮显示文本块并键入字母(例如字母”y”)后,它将删除高亮显示的文本并插入字母”y”。如果您使用逐行选择模式(gH)高亮显示一行文本并键入”y”,它将删除高亮显示的文本并插入字母”y”,这与常规文本编辑器非常相似。
将此行为与可视模式进行对比:如果您使用逐行可视模式(V)高亮显示一行文本并键入”y”,则高亮显示的文本不会被删除且被字母”y”代替,而是仅将其复制(yank)。在选择模式中,你不能执行对高亮文本执行普通模式的命令。
我个人从未使用过选择模式,但是很高兴知道它的存在。
以聪明的方式学习可视模式
可视模式是Vim高亮显示文本的过程。
如果发现使用可视模式操作的频率比正常模式操作的频率高得多,请当心。我认为这是一种反模式。运行可视模式操作所需的击键次数要多于普通模式下的击键次数。假设您需要删除一个内部单词(inner word,请回顾前面的文本对象),如果可以只用三个按键(diw),为什么要使用四个按键viwd(先v进入可视模式,然后iw高亮一个内部单词,最后d删除)呢?前者更为直接和简洁。当然,有时使用可视模式是合适的,但总的来说,更倾向于直接的方法。
第12章 搜索和替换
本章涵盖两个独立但相关的概念:搜索和替代。很多时候,您得基于文本的共同模式搜索大量的内容。通过学习如何在搜索和替换中使用正则表达式而不是字面字符串,您将能够快速定位任何文本。
附带说明一下,在本章中,当谈论搜索时,我将主要使用/。您使用/进行的所有操作也可以使用?完成。
智能区分大小写
尝试匹配搜索词的大小写可能会很棘手。如果要搜索文本”Learn Vim”,则很容易把字母的大小写输错,从而得到错误的搜索结果。如果可以匹配任何情况,会不会更轻松,更安全?这是选项ignorecase闪亮的地方。只需在 vimrc 中添加set ignorecase,所有搜索词就不区分大小写。现在,您不必再执行/Learn Vim了。 /learn vim将起作用。
但是,有时您需要搜索特定大小写的短语。一种方法是用 set noignorecase 关闭ignorecase选项,但是每次需要搜索区分大小写的短语时,都得反复地打开和关闭这个选项。
为避免反复开关ignorecase选项,Vim 有一个smartcase选项。您可以将ignorecase和smartcase选项结合起来,当您输入的搜索词全部是小写时,进行大小写不敏感搜索;而当搜索词 至少有1个大写字母时,进行大小写敏感搜索。
在您的 vimrc 中,添加:
set ignorecase smartcase
如果您有这些文字:
hello
HELLO
Hello
/hello匹配”hello”,”HELLO”和”Hello”。/HELLO仅匹配”HELLO”。/Hello仅匹配”Hello”。
有一个缺点。因为现在当您执行/hello时,Vim 将进行大小写不敏感搜索,那如果只需要搜索小写字符串怎么办?您可以在搜索词前使用\C模式来告诉 Vim,后续搜索词将区分大小写。如果执行/\Chello,它将严格匹配”hello”,而不是”HELLO”或”Hello”。
一行中的第一个和最后一个字符
您可以使用^匹配行中的第一个字符,并使用$匹配行中的最后一个字符。
如果您有以下文字:
hello hello
您可以使用/^hello来定位第一个”hello”。 ‘^’后面的字符必须是一行中的第一个字符。 要定位最后一个”hello”,请运行/hello$。 ‘$’ 之前的字符必须是一行中的最后一个字符。
如果您有以下文字:
hello hello friend
运行/hello$将匹配不到任何内容,因为”friend”是该行的最后一项,而不是”hello”。
重复搜索
您可以使用//重复上一个搜索。如果您只是搜索/hello,则运行//等同于运行/hello。此快捷键可以为您节省一些按键操作,尤其是在您刚搜索了一个很长的字符串的情况下。另外,回想一下前面的章节,您还可以使用n和N分别以相同方向和相反方向重复上一次搜索。
如果您想快速回忆起 第n个最近使用的搜索字怎么办?您可以先按/,然后按up/down方向键(或Ctrl-N/Ctrl-P),快速遍历搜索历史,直到找到所需的搜索词。要查看所有搜索历史,可以运行:history /。
在搜索过程中到达文件末尾时,Vim 会抛出一个错误:"搜索到达底部,未找到匹配项:{your-search}"("Search hit the BOTTOM without match for: {your-search}")。有时这个特性能成为一个安全守卫,可以防止过度搜索,但是有时您又想将搜索重新循环到顶部。您可以使用set wrapscan选项使 Vim 在到达文件末尾时回到文件顶部进行搜索。要关闭此功能,请执行set nowrapscan。
使用候选词搜索
一次搜索多个单词属于日常操作。 如果您需要搜索”hello vim”或”hola vim”,而不是”salve vim”或”bonjour vim”,则可以使用|或运算符。
给予这样一段文本:
hello vim
hola vim
salve vim
bonjour vim
要同时匹配”hello”和”hola”,可以执行/hello\|hola。 您必须使用(\)转义(|)或运算符,否则 Vim 将按字面意义搜索字符串” |
“。 |
如果您不想每次都输入\|,则可以在搜索开始时使用magic语法(\v):/\vhello|hola。 我不会在本章中详细介绍magic,但是有了\v,您就不必再转义特殊字符了。 要了解有关\v的更多信息,请随时查看:h \v。
设置模式匹配的开始位置和结束位置
也许您需要搜索的文本是复合词的一部分。如果您有这些文字:
11vim22
vim22
11vim
vim
如果您仅需要选择以”11”开始、以”22”结束的”vim”,您可以使用\zs(开始匹配)和\ze(结束匹配)运算符。 执行:
/11\zsvim\ze22
Vim仍然会匹配整个模式”11vim22”,但是仅高亮显示介于\zs和\ze之间的内容。 另一个例子:
foobar
foobaz
如果需要在”foobaz”中搜索”foo”,而不是在”foobar”中搜索,请运行:
/foo\zebaz
搜索字符组
到目前为止,您所有的搜索字都是字面内容。在现实生活中,您可能必须使用通用模式来查找文本。最基本的模式是字符组[ ]。
如果您需要搜索任何数字,则可能不想每一次都输入/0\|1\|2\|3\|4\|5\|6\|7\|8\|9\|0。相反,请使用/[0-9]来匹配一位数字。 0-9表达式表示 Vim 尝试匹配的数字范围是 0-9,因此,如果要查找 1 到 5 之间的数字,请使用/[1-5]。
数字不是 Vim 可以查找的唯一数据类型。您也可以执行/[a-z]来搜索小写字母,而/[A-Z]来搜索大写字母。
您可以将这些范围组合在一起。如果您需要搜索数字 0-9 以及从 a 到 f(十六进制)的小写字母和大写字母,可以执行/[0-9a-fA-F]。
要进行否定搜索,可以在字符范围括号内添加^。要搜索非数字,请运行/[^0-9],Vim会匹配任何字符,只要它不是数字即可。请注意,范围括号内的脱符号(^)与行首位置符号(例如:/^hello)不同。如果插入号在一对方括号之外,并且是搜索词中的第一个字符,则表示”一行中的第一个字符”。如果插入符号在一对方括号内,并且是方括号内的第一个字符,则表示否定搜索运算符。 /^abc匹配行中的第一个”abc”,而/[^abc]匹配除”a”,”b”或”c”以外的任何字符。
搜索重复字符
如果需要在此文本中搜索两位数:
1aa
11a
111
您可以使用/[0-9][0-9]来匹配两位数字字符,但是该方法难以扩展。 如果您需要匹配二十个数字怎么办? 打字 20 次[[0-9]]并不是一种有趣的体验。 这就是为什么您需要一个count参数。
您可以将count传递给您的搜索。 它具有以下语法:
{n,m}
顺便说一句,当在 Vim 中使用它们时,这些count周围的花括号需要被转义。 count 运算符放在您要递增的单个字符之后。
这是count语法的四种不同变体:
{n}是精确匹配。/[0-9]\{2\}匹配两个数字:”11”,以及”111”中的”11”。{n,m}是范围匹配。/[0-9]\{2,3\}匹配 2 到 3 位数字:”11”和”111”。{,m}是上限匹配。/[0-9]\{,3\}匹配最多 3 个数字:”1”,”11”和”111”。{n,}是下限匹配。/[0-9]\{2,\}匹配最少 2 个或多个数字:”11”和”111”。
计数参数\{0,\}(零或多个)和\{1,\}(一个或多个)是最常见的搜索模式,Vim 为它们提供了特殊的操作符:*和+( +需要被转义,而* 可以正常运行而无需转义)。 如果执行/[0-9]*,功能与/[0-9]\{0,\}相同。 它搜索零个或多个数字,会匹配”“,”1”,”123”。 顺便说一句,它也将匹配非数字,例如”a”,因为在技术上,字母”a”中的数字个数为零。 在使用”*“之前,请仔细考虑。 如果执行/[0-9]\+,则与/[0-9]\{1,\}相同。 它搜索一个或多个数字,将匹配”1”和”12”。
预定义的字符组
Vim 为常见字符组(例如数字和字母)提供了简写。 我不会在这里逐一介绍,但可以在:h /character-classes中找到完整列表。 下面是有用的部分:
\d 数字[0-9]
\D 非数字[^ 0-9]
\s 空格字符(空格和制表符)
\S 非空白字符(除空格和制表符外的所有字符)
\w 单词字符[0-9A-Za-z_]
\l 小写字母[a-z]
\u 大写字符[A-Z]
您可以像使用普通字符组一样使用它们。 要搜索任何一位数字,可以使用/\d以获得更简洁的语法,而不使用/[0-9]。
搜索示例:在一对相似字符之间捕获文本
如果要搜索由双引号引起来的短语:
"Vim is awesome!"
运行这个:
`/"[^"]\+"`
让我们分解一下:
"是字面双引号。它匹配第一个双引号。[^"]表示除双引号外的任何字符,只要不是双引号,它就与任何字母数字和空格字符匹配。\+表示一个或多个。因为它的前面是[^"],因此 Vim 查找一个或多个不是双引号的字符。"是字面双引号。它与右双引号匹配。
当看到第一个"时,它开始模式捕获。Vim 在一行中看到第二个双引号时,它匹配第二个"模式并停止模式捕获。同时,两个双引号之间的所有非双引号字符都被[^"]\+ 模式捕获,在这个例子中是短语”Vim is awesome!”。这是一个通用模式(其实就是正则表达式)用于捕获 由一对类似的定界符包围的短语。
- 要捕获被单引号包围的短语,你可以使用
/'[^']\+' - 要捕获为0包围的短语,你可以使用
/0[^0]\+0
搜索示例:捕获电话号码
如果要匹配以连字符(-)分隔的美国电话号码,例如123-456-7890,则可以使用:
/\d\{3\}-\d\{3\}-\d\{4\}
美国电话号码的组成是:首先是三位数字,其后是另外三位数字,最后是另外四位数字。 让我们分解一下:
\d\{3\}与精确重复三次的数字匹配-是字面的连字符
为避免转义,可使用\v:
/\v\d{3}-\d{3}-\d{4}
此模式还可用于捕获任何重复的数字,例如 IP 地址和邮政编码。
这涵盖了本章的搜索部分。 现在开始讲替换。
基本替换
Vim 的替代命令是一个有用的命令,用于快速查找和替换任何模式。 替换语法为:
:s/{old-pattern}/{new-pattern}/
让我们从一个基本用法开始。 如果您有以下文字:
vim is good
让我们用”awesome”代替”good”,因为 Vim 很棒。 运行:s/good/awesome/.您应该看到:
vim is awesome
重复最后一次替换
您可以使用普通模式命令&或运行:s来重复最后一个替代命令。 如果您刚刚运行:s/good/awesome/,则运行&或:s将会重复执行。
另外,在本章前面,我提到您可以使用//来重复先前的搜索模式。 此技巧可用于替代命令。 如果/good是最近被替换的单词,那么将第一个替换模式参数留为空白,例如在:s//awesome/中,则与运行:s/good/awesome/相同。
替换范围
就像许多 Ex 命令一样,您可以将范围参数传递给替换命令。 语法为:
:[range]s/old/new/
如果您有以下表达式:
let one = 1;
let two = 2;
let three = 3;
let four = 4;
let five = 5;
要将第3行到第5行中的”let”替换为”const”,您可以执行以下操作:
:3,5s/let/const/
下面是一些你可以使用的范围参数的变体:
:,3/let/const/- 如果逗号前没有给出任何内容,则表示当前行。 从当前行替换到第 3 行。:1,s/let/const/- 如果逗号后没有给出任何内容,它也代表当前行。 从第 1 行替换到当前行。:3s/let/const/- 如果仅给出一个值作为范围(不带逗号),则仅在该行进行替换。
在 Vim 中,%通常表示整个文件。 如果运行:%s/let/const/,它将在所有行上进行替换。请记住这个范围参数语法,在后面章节中很多命令行命令都遵循这个语法。
模式匹配
接下来的几节将介绍基本的正则表达式。 丰富的模式知识对于掌握替换命令至关重要。
如果您具有以下表达式:
let one = 1;
let two = 2;
let three = 3;
let four = 4;
let five = 5;
要在数字周围添加一对双引号:
:%s/\d/"\0"/
结果:
let one = "1";
let two = "2";
let three = "3";
let four = "4";
let five = "5";
让我们分解一下命令:
:%s定位整个文件以执行替换。\d是 Vim 的预定义数字范围简写(类似使用[0-9])。"\0"双引号是双引号的字面值。\0是一个特殊字符,代表”整个匹配的模式”。 此处匹配的模式是单个数字\d。
另外,&也同样代表”整个匹配的模式”,就像\0一样。 :s/\d/"&"/也可以。
让我们考虑另一个例子。 给出以下表达式,您需要将所有的”let”和变量名交换位置:
one let = "1";
two let = "2";
three let = "3";
four let = "4";
five let = "5";
为此,请运行:
:%s/\(\w\+\) \(\w\+\)/\2 \1/
上面的命令包含太多的反斜杠,很难阅读。 使用\v运算符更方便:
:%s/\v(\w+) (\w+)/\2 \1/
结果:
let one = "1";
let two = "2";
let three = "3";
let four = "4";
let five = "5";
太好了! 让我们分解该命令:
:%s定位文件中的所有行以执行替换操作(\w+) (\w+)对模式进行分组。\w是 Vim 预定义的单词字符范围简写([0-9A-Za-z_])之一。 包围\w的()将匹配的单词字符进行分组。 请注意两个分组之间的空间。(\w+) (\w+)捕获两个分组。 在第一行上,第一组捕获”let”,第二组捕获”one”。(英文版中,作者写成了:第一组捕获”one”,第二组捕获”two”,可能是作者不小心的错误)。\2 \1以相反的顺序返回捕获的组。\2包含捕获的字符串”let”,而\1包含字符串”one”。 使\2 \1返回字符串”let one”。
回想一下,\0代表整个匹配的模式。 您可以使用( )将匹配的字符串分成较小的组。 每个组都由\1, \2, \3等表示。
让我们再举一个例子来巩固这一匹配分组的概念。 如果您有以下数字:
123
456
789
要颠倒顺序,请运行:
:%s/\v(\d)(\d)(\d)/\3\2\1/
结果是:
321
654
987
每个(\d)都匹配一个数字并创建一个分组。 在第一行上,第一个(\d)的值为”1”,第二个(\d)的值为”2”,第三个(\d)的值为”3”。 它们存储在变量\1,\2和\3中。 在替换的后半部分,新模式\3\2\1在第一行上产生”321”值。
相反,如果您运行下面的命令:
:%s/\v(\d\d)(\d)/\2\1/
您将获得不同的结果:
312
645
978
这是因为您现在只有两个组。 被(\d\d)捕获的第一组存储在\1内,其值为”12”。 由(\d)捕获的第二组存储在\2内部,其值为”3”。 然后,\2\1返回”312”。
替换标志
如果您有以下句子:
chocolate pancake, strawberry pancake, blueberry pancake
要将所有 pancakes 替换为 donut,您不能只运行:
:s/pancake/donut
上面的命令将仅替换第一个匹配项,返回的结果是:
chocolate donut, strawberry pancake, blueberry pancake
有两种解决方法。 一,您可以再运行两次替代命令。 二,您可以向其传递全局(g)标志来替换一行中的所有匹配项。
让我们谈谈全局标志。 运行:
:s/pancake/donut/g
Vim 迅速将所有”pancake”替换为”donut”。 全局命令是替代命令接受的几个标志之一。 您在替代命令的末尾传递标志。 这是有用的标志的列表:
& 重用上一个替代命令中的标志。 必须作为第一个标志传递。
g 替换行中的所有匹配项。
c 要求替代确认。
e 防止替换失败时显示错误消息。
i 执行不区分大小写的替换
I 执行区分大小写的替换
我上面没有列出更多标志。 要了解所有标志,请查看:h s_flags。
顺便说一句,重复替换命令(&和:s)不保留标志。 运行&只会重复:s/pancake/donut/而没有g。 要使用所有标志快速重复最后一个替代命令,请运行:&&。
更改定界符
如果您需要用长路径替换 URL:
https://mysite.com/a/b/c/d/e
要用单词”hello”代替它,请运行:
:s/https:\/\/mysite.com\/a\/b\/c\/d\/e/hello/
但是,很难说出哪些正斜杠(/)是替换模式的一部分,哪些是分隔符。 您可以使用任何单字节字符(除字母,数字或",|和\之外的字符)来更改定界符。让我们将它们替换为+。上面的替换命令可以重写为 :
:s+https:\/\/mysite.com\/a\/b\/c\/d\/e+hello+
现在,更容易看到分隔符在哪里。
特殊替换
您还可以修改要替换的文本的大小写。 给出以下表达式,您的任务是将所有变量名比如 “one”, “two”, “three”等,改成大写:
let one = "1";
let two = "2";
let three = "3";
let four = "4";
let five = "5";
请运行:
%s/\v(\w+) (\w+)/\1 \U\2/
你会得到:
let ONE = "1";
let TWO = "2";
let THREE = "3";
let FOUR = "4";
let FIVE = "5";
这是该命令的细分:
(\w+) (\w+)捕获前两个匹配的分组,例如”let”和”one”。\1返回第一个组的值”let”\U\2大写(\U)第二组(\2)。
该命令的窍门是表达式\U\2。\U将后面跟着的字符变为大写。
让我们再举一个例子。 假设您正在编写 Vim 书籍,并且需要将一行中每个单词的首字母大写。
vim is the greatest text editor in the whole galaxy
您可以运行:
:s/\<./\U&/g
结果:
Vim Is The Greatest Text Editor In The Whole Galaxy
细目如下:
:s替换当前行\<.由两部分组成:\<匹配单词的开头,.匹配任何字符。\<运算符使后面跟着的字符表示单词的第一个字符。 由于.是下一个字符,因此它将匹配任意单词的第一个字符。\U&将后续符号子序列&大写。 回想一下,&(或\0)代表整个匹配。 这里它匹配单词的第一个字符。g全局标志。 没有它,此命令将仅替换第一个匹配项。 您需要替换此行上的每个匹配项。
要了解替换的特殊替换符号(如\u和\U)的更多信息,请查看:h sub-replace-special。
候选模式
有时您需要同时匹配多个模式。 如果您有以下问候:
hello vim
hola vim
salve vim
bonjour vim
您仅需在包含单词”hello”或”hola”的行上用”friend”代替”vim”。回想一想本章前面的知识点,你可以使用| 来分隔可选的模式:
:%s/\v(hello|hola) vim)/\1 friend/g
结果:
hello friend
hola friend
salve vim
bonjour vim
这是细分:
%s在文件的每一行上运行替代命令。(hello|hola)匹配*“hello”或”hola”,并将其视为一个组。vim是字面意思”vim”。\1是第一个匹配组,它是文本”hello”或”hola”。friend是字面的“朋友”。
指定替换模式的开始位置和结束位置
回想一下,您可以使用\zs和\ze来指定一个匹配的开始位置和结束位置。这个技术在替换操作中同样有效,如果你有以下文本:
chocolate pancake
strawberry sweetcake
blueberry hotcake
要想将”hotcake”中的”cake”替换为”dog”,得到”hotdog”:
:%s/hot\zscake/dog/g
结果是:
chocolate pancake
strawberry sweetcake
blueberry hotdog
贪婪与非贪婪
您可以使用下面技巧,在某行中替换第n个匹配:
One Mississippi, two Mississippi, three Mississippi, four Mississippi, five Mississippi.
要想将第3个”Mississippi”替换为 “Arkansas”,运行:
:s/\v(.{-}\zsMississippi){3}/Arkansas/g
命令分解:
:s/替换命令。\v魔术关键字,使您不必转义特殊字符。.匹配任意单个字符。{-}表示使用非贪婪模式匹配前面的0个或多个字符。\zsMississippi使得从”Mississippi”开始捕获匹配。(...){3}查找第3个匹配
在本章前面的内容中,你已经看到过{3}这样的语法。在本例中,{3}将精确匹配第3个匹配。这里的新技巧是{-}。它表示进行非贪婪匹配。它会找到符合给定模式的最短的匹配。在本例中,(.{-}Mississippi)匹配以任意字符开始、数量最少的”Mississippi”。对比(.*Mississippi),后者会找到符合给定模式的最长匹配。
如果您使用(.{-}Mississippi),你会得到5个匹配:”One Mississippi”, “Two Mississippi”,等。如果您使用(.*Mississippi),您只会得到1个匹配:最后一个 “Mississippi”。*表示贪婪匹配,而{-}表示非贪婪匹配。要想了解更多,可以查看 :h /\{- 和 :h non-greedy。
让我们看一个简单的例子。如果您有以下字符串:
abc1de1
用贪婪模式匹配 “abc1de1” :
/a.*1
用非贪婪模式匹配 “abc1”:
/a.\{-}1
因此,如果您需要将最长的匹配转为大写(贪婪模式),运行:
:s/a.*1/\U&/g
会得到:
ABC1DE1
如果您需要将最短的匹配转为大写(非贪婪模式),运行:
:s/a.\{-}1/\U&/g
会得到:
ABC1de1
如果您是第一次接触贪婪模式与非贪婪模式这两个概念,可能会把你绕晕。围绕不同的组合去实验,知道您明白这两个概念。
跨多个文件替换
最后,让我们学习如何在多个文件中替换短语。对于本节,假设您有两个文件: food.txt 和 animal.txt.
food.txt内:
corn dog
hot dog
chili dog
animal.txt内:
large dog
medium dog
small dog
假设您的目录结构如下所示:
├ food.txt
├ animal.txt
首先,用:args同时捕获”food.txt”和”animal.txt”到参数列表中。回顾前面的章节,:args可用于创建文件名列表。在 Vim 中有几种方法可以做到这一点,其中一种方法是在Vim内部运行:
:args *.txt 捕获当前位置的所有txt文件
测试一下,当您运行:args时,您应该会看到:
[food.txt] animal.txt
现在,所有的相关文件都已经存储在参数列表中,您可以用 :argdo 命令跨多文件替换,运行:
:argdo %s/dog/chicken/
这条命令对所有:args列表中的文件执行替换操作。最终,存储修改的文件:
:argdo update
:args 和 :argdo 是两个有用的工具,用于跨多文件执行命令行命令。可以用其他命令结合尝试一下!
用宏跨多个文件替换
另外,您也可以用宏跨多个文件运行替代命令。执行:
:args *.txt
qq
:%s/dog/chicken/g
:wnext
q
99@q
以下是步骤的细分:
:args *.txt会将相关文件列出到:args列表中。qq启动”q”寄存器中的宏。:%s/dog/chicken/g在当前文件的所有行上用”chicken”替换”dog”。:wnext写入(保存)文件,然后转到args列表中的下一个文件。就像同时运行:w和:next一样。q停止宏录制。99@q执行宏九十九次。 Vim 遇到第一个错误后,它将停止执行宏,因此 Vim 实际上不会执行该宏九十九次。
以聪明的方式学习搜索和替换
良好的搜索能力是编辑的必要技能。掌握搜索功能使您可以利用正则表达式的灵活性来搜索文件中的任何模式。花些时间学习这些。要想掌握正则表达式,您必须在实践中去不断地使用它。我曾经读过一本关于正则表达式的书,却没有真正去做,后来我几乎忘了读的所有东西。主动编码是掌握任何技能的最佳方法。
一种提高模式匹配技能的好方法是,每当您需要搜索一个模式串时(例如”hello 123”),不要直接查询文字的字面值(/hello 123),去尝试使用模式串来搜索它(比如/\v(\l+) (\d+))。这些正则表达式概念中的许多不仅在使用 Vim 时,也适用于常规编程。
既然您已经了解了 Vim 中的高级搜索和替换,现在让我们学习功能最丰富的命令之一,即全局命令。
第13章 全局命令
到目前为止,您已经了解了如何使用点命令(.)重复上一次更改,如何使用宏(q)重复动作以及将文本存储在寄存器中(")。
在本章中,您将学习如何在全局命令中重复命令行命令。
全局命令概述
Vim的全局命令用于同时在多行上运行命令行命令。
顺便说一句,您之前可能已经听说过 “Ex命令” 一词。在本书中,我将它们称为命令行命令,但Ex命令和命令行命令是相同的。它们是以冒号(:)开头的命令。在上一章中,您了解了替代命令。这是一个Ex命令的示例。它们之所以称为Ex,是因为它们最初来自Ex文本编辑器。在本书中,我将继续将它们称为命令行命令。有关Ex命令的完整列表,请查看:h ex-cmd-index。
全局命令具有以下语法:
:g/pattern/command
pattern匹配包含该模式串的所有行,类似于替代命令中的模式串。command可以是任何命令行命令。全局命令通过对与pattern匹配的每一行执行command来工作。
如果您具有以下表达式:
const one = 1;
console.log("one: ", one);
const two = 2;
console.log("two: ", two);
const three = 3;
console.log("three: ", three);
要删除所有包含”console”的行,可以运行:
:g/console/d
结果:
const one = 1;
const two = 2;
const three = 3;
全局命令在与”console”模式串匹配的所有行上执行删除命令(d)。
运行g命令时,Vim对文件进行两次扫描。在第一次运行时,它将扫描每行并标记与/console/模式传教匹配的行。一旦所有匹配的行都被标记,它将进行第二次运行,并在标记的行上执行d命令。
如果要删除所有包含”const”的行,请运行:
:g/const/d
结果:
console.log("one: ", one);
console.log("two: ", two);
console.log("three: ", three);
逆向匹配
要在不匹配的行上运行全局命令,可以运行:
:g!/{pattern}/{command}
或者
:v/{pattern}/{command}
如果运行:v/console/d,它将删除 不 包含”console”的所有行。
模式串
全局命令使用与替代命令相同的模式串系统,因此本节将作为更新。随意跳到下一部分或继续阅读!
如果您具有以下表达式:
const one = 1;
console.log("one: ", one);
const two = 2;
console.log("two: ", two);
const three = 3;
console.log("three: ", three);
要删除包含”one”或”two”的行,请运行:
:g/one\|two/d
要删除包含任何一位数字的行,请运行以下任一命令:
:g/[0-9]/d
或者
:g/\d/d
如果您有表达式:
const oneMillion = 1000000;
const oneThousand = 1000;
const one = 1;
要匹配包含三到六个零的行,请运行:
:g/0\{3,6\}/d
传递范围参数
您可以在g命令之前传递一个范围。您可以通过以下几种方法来做到这一点:
:1,5/g/console/d删除第1行和第5行之间匹配字符串”console”的行。:,5/g/console/d如果逗号前没有地址,则从当前行开始。它在当前行和第5行之间寻找字符串”console”并将该行删除。:3,/g/console/d如果逗号后没有地址,则在当前行结束。它在第3行和当前行之间寻找字符串”console”并将该行删除。:3g/console/d如果只传递一个地址而不带逗号,则仅在第3行执行命令。在第3行查找,如果包含字符串”console”,则将其删除。
除了数字,您还可以将这些符号用作范围:
.表示当前行。范围.,3表示当前行和第3行之间。$表示文件的最后一行。3,$范围表示在第3行和最后一行之间。+n表示当前行之后的n行。您可以将其与.结合使用,也可以不结合使用。3,+1或3,.+1表示在第3行和当前行之后的行之间。
如果您不给它任何范围,默认情况下它将影响整个文件。这实际上不是常态。如果您不传递任何范围,Vim的大多数命令行命令仅在当前行上运行(两个值得注意的例外是:这里介绍的全局命令(:g)和save(:w)命令)。
普通模式命令
您可以将全局命令和:normal命令行命令一起运行。
如果您有以下文字:
const one = 1
console.log("one: ", one)
const two = 2
console.log("two: ", two)
const three = 3
console.log("three: ", three)
要添加”;”运行到每一行的末尾:
:g/./normal A;
让我们分解一下:
:g是全局命令。/./是“非空行”的模式。它匹配至少包含1个字符的行。因此将与包含“const”和“console”的行匹配。它不匹配空行。normal A;运行:normal命令行命令。A;是普通模式命令,用于在该行的末尾插入”;”。
执行宏
您也可以使用全局命令执行宏。宏只是普通模式下的操作,因此可以使用:normal来执行宏。如果您有以下表达式:
const one = 1
console.log("one: ", one);
const two = 2
console.log("two: ", two);
const three = 3
console.log("three: ", three);
请注意,带有”const”的行没有分号。让我们创建一个宏,以在寄存器”a”的这些行的末尾添加逗号:
qa0A;<esc>q
如果您需要复习,请查看有关宏的章节。现在运行:
:g/const/normal @a
现在,所有带有”const”的行的末尾将带有”;”。
const one = 1;
console.log("one: ", one);
const two = 2;
console.log("two: ", two);
const three = 3;
console.log("three: ", three);
如果您一步一步按照示例做,您将会在第一行末尾看到两个分号。为避免这种情况,使用全局命令时,给一个范围参数,从第2行到最后一行, :2,$g/const/normal @a。
递归全局命令
全局命令本身是命令行命令的一种,因此您可以从技术上在全局命令中运行全局命令。
给定表达式:
const one = 1;
console.log("one: ", one);
const two = 2;
console.log("two: ", two);
const three = 3;
console.log("three: ", three);
如果您运行:
:g/console/g/two/d
首先,g将查找包含模式”console”的行,并找到3个匹配项。然后,第二个”g”将从那三个匹配项中查找包含模式”two”的行。最后,它将删除该匹配项。
您也可以将g与v结合使用以找到正负模式。例如:
:g/console/v/two/d
与前面的命令不同,它将查找 不 包含”two”的行。
更改定界符
您可以像替代命令一样更改全局命令的定界符。规则是相同的:您可以使用任何单字节字符,但字母,数字,", |, 和 \除外。
要删除包含”console”的行:
:g@console@d
如果在全局命令中使用替代命令,则可以有两个不同的定界符:
g@one@s+const+let+g
此处,全局命令将查找包含”one”的所有行。 替换命令将从这些匹配项中将字符串”const”替换为”let”。
默认命令
如果在全局命令中未指定任何命令行命令,会发生什么?
全局命令将使用打印(:p)命令来打印当前行的文本。如果您运行:
:g/console
它将在屏幕底部打印所有包含”console”的行。
顺便说一下,这是一个有趣的事实。因为全局命令使用的默认命令是p,所以这使g语法为:
:g/re/p
g= 全局命令re= 正则表达式模式p= 打印命令
这三个元素连起来拼写为 “grep”,与命令行中的grep 相同。但这 不 是巧合。 g/re/p命令最初来自Ed编辑器(一个行文本编辑器)。 grep命令的名称来自Ed。
您的计算机可能仍具有Ed编辑器。从终端运行ed(提示:要退出,请键入q)。
反转整个缓冲区
要翻转整个文件,请运行:
:g/^/m 0
^表示行的开始。使用^匹配所有行,包括空行。
如果只需要反转几行,请将其传递一个范围。要将第5行到第10行之间的行反转,请运行:
:5,10g/^/m 0
要了解有关move命令的更多信息,请查看:h :move。
汇总所有待办事项
当我编码时,有时我会想到一个随机的绝妙主意。不想失去专注,我通常将它们写在我正在编辑的文件中,例如:
const one = 1;
console.log("one: ", one);
// TODO: 喂小狗
const two = 2;
// TODO:自动喂小狗
console.log("two: ", two);
const three = 3;
console.log("three: ", three);
// TODO:创建一家销售自动小狗喂食器的初创公司
跟踪所有已创建的TODO可能很困难。 Vim有一个:t(copy)方法来将所有匹配项复制到一个地址。要了解有关复制方法的更多信息,请查看:h :copy。
要将所有TODO复制到文件末尾以便于自省,请运行:
:g/TODO/t $
结果:
const one = 1;
console.log("one: ", one);
// TODO:喂小狗
const two = 2;
// TODO:自动喂小狗
console.log("two: ", two);
const three = 3;
console.log("three: ", three);
// TODO:创建一家销售自动小狗喂食器的初创公司
// TODO:喂小狗
// TODO:自动喂小狗
// TODO:创建一家销售自动小狗喂食器的初创公司
现在,我可以查看我创建的所有TODO,另外找个时间来完成它们,或将它们委托给其他人,然后继续执行下一个任务。
如果不想复制,而是将所有的 TODO 移动到末尾,可以使用移动命令 m:
:g/TODO/m $
结果:
const one = 1;
console.log("one: ", one);
const two = 2;
console.log("two: ", two);
const three = 3;
console.log("three: ", three);
// TODO:喂小狗
// TODO:自动喂小狗
// TODO:创建一家销售自动小狗喂食器的初创公司
黑洞删除
回想一下寄存器那一章,已删除的文本存储在编号寄存器中(允许它们足够大)。每当运行:g/console/d时,Vim都会将删除的行存储在编号寄存器中。如果删除多行,所有编号的寄存器将很快被填满。为了避免这种情况,您可以使用黑洞寄存器("_) 不 将删除的行存储到寄存器中。
:g/console/d _
通过在d之后传递_,Vim不会将删除的行保存到任何寄存器中。
将多条空行减少为一条空行
如果您的文件带有多个空行,如下所示:
const one = 1;
console.log("one: ", one);
const two = 2;
console.log("two: ", two);
const three = 3;
console.log("three: ", three);
您可以快速将多个空行减少为一条空行。运行:
:g/^$/,/./-1j
结果:
const one = 1;
console.log("one: ", one);
const two = 2;
console.log("two: ", two);
const three = 3;
console.log("three: ", three);
一般情况下全局命令遵循下列格式::g/pattern/command。但是,您也可以使用下面的格式::g/pattern1/,/pattern2/command。用这种格式,Vim将会使command作用在pattern1和pattern2上。
记住上面说的格式,让我们根据:g/pattern1/,/pattern2/command这个格式分解一下命令:g/^$/,/./-1j:
/pattern1/就是/^$/。它表示一个空行(一个没有任何字符的行)。/pattern2/就是/./(用-1作为行修正)。/./表示一个非空行(一个含有至少1个字符的行)。这里的-1意思是向上偏移1行。command就是j,一个联接命令(:j)。在这个示例中,该全局命令联接所有给定的行。
顺便说一句,如果您想要将多个空行全部删去,运行下面的命令:
:g/^$/,/./j
或者:
:g/^$/-j
您的文本将会减少为:
const one = 1;
console.log("one: ", one);
const two = 2;
console.log("two: ", two);
const three = 3;
console.log("three: ", three);
(译者补充:j连接命令的格式是::[range]j。比如::1,5j将连接第1至5行。在前面的命令中:g/pattern1/,/pattern2/-1j,/pattern1/和/pattern2都是j命令的范围参数,表示连接空行至非空行上方一行,这样就会保留1个空行。在早前的英文版本中有关于j命令的介绍,不知为何在后面的更新中,原作者删除了关于j命令的介绍)
高级排序
Vim有一个:sort命令来对一个范围内的行进行排序。例如:
d
b
a
e
c
您可以通过运行:sort对它们进行排序。如果给它一个范围,它将只对该范围内的行进行排序。例如,:3,5sort仅在第三和第五行之间排序。
如果您具有以下表达式:
const arrayB = [
"i",
"g",
"h",
"b",
"f",
"d",
"e",
"c",
"a",
]
const arrayA = [
"h",
"b",
"f",
"d",
"e",
"a",
"c",
]
如果需要排序数组中的元素,而不是数组本身,可以运行以下命令:
:g/\[/+1,/\]/-1sort
结果:
const arrayB = [
"a",
"b",
"c",
"d",
"e",
"f",
"g",
"h",
"i",
]
const arrayA = [
"a"
"b",
"c",
"d",
"e",
"f",
"h",
]
这很棒!但是命令看起来很复杂。让我们分解一下。该命令依然遵循 :g/pattern1/,/pattern2/command这个格式。
:g是全局命令/\[/+1是第一个模式串,它匹配左方括号”[“。+1表示匹配行的下面1行。/\[/-1是第二个模式串,它匹配右方括号”]”。-1表示匹配行的上面1行。/\[/+1,/\]/-1表示在”[“和”]”之间的行。sort是命令行命令:排序。
聪明地学习全局命令
全局命令针对所有匹配的行执行命令行命令。有了它,您只需要运行一次命令,Vim就会为您完成其余的工作。要精通全局命令,需要做两件事:良好的命令行命令词汇表和正则表达式知识。随着您花费更多的时间使用Vim,您自然会学到更多的命令行命令。正则表达式知识需要更多的实际操作。但是一旦您适应了使用正则表达式,您将领先于很多其他人。
这里的一些例子很复杂。不要被吓到。真正花时间了解它们。认真阅读每个模式串,不要放弃。
每当需要在多个位置应用命令时,请暂停并查看是否可以使用g命令。寻找最适合工作的命令,并编写一个模式串以同时定位多个目标。
既然您已经知道全局命令的功能强大,那么让我们学习如何使用外部命令来增加工具库。
第14章 外部命令
在Unix系统内部,您会发现许多小型的,超专业化命令,每个命令只做一件事(而且能很好地完成)。您可以将这些命令链接在一起以共同解决一个复杂的问题。如果可以从Vim内部使用这些命令,那不是很好吗?
答案是肯定的!在本章中,您将学习如何扩展Vim以使其与外部命令无缝协作。
Bang 命令
Vim有一个Bang(!)命令,可以执行三件事:
1.将外部命令的STDOUT读入当前缓冲区。 2.将缓冲区的内容作为STDIN写入外部命令。 3.从Vim内部执行外部命令。
让我们一个个认真看一下。
将外部命令的标准输出STDOUT读入Vim
将外部命令的STDOUT读入当前缓冲区的语法为:
:r !{cmd}
:r是Vim的读命令。如果不带!使用它,则可以使用它来获取文件的内容。如果当前目录中有文件file1.txt,运行:
:r file1.txt
Vim会将file1.txt的内容放入当前缓冲区。
如果您运行的:r命令后面跟一个!和外部命令,则该命令的输出将插入到当前缓冲区中。要获取ls命令的结果,请运行:
:r !ls
它返回类似下列的文本:
file1.txt
file2.txt
file3.txt
您可以从curl命令读取数据:
:r !curl -s 'https://jsonplaceholder.typicode.com/todos/1'
r命令也接受一个地址:
:10r !cat file1.txt
现在,将在第10行之后插入来自运行cat file.txt的STDOUT。
将缓冲区内容写入外部命令
:w命令除了保存文件,还可以用来将当前缓冲区中的文本作为作为STDIN传递给外部命令。语法为:
:w !cmd
如果您具有以下表达式:
console.log("Hello Vim");
console.log("Vim is awesome");
确保在计算机中安装了node,然后运行:
:w !node
Vim将使用node执行Javascript表达式来打印”Hello Vim”和”Vim is awesome”。
当使用:w命令时,Vim使用当前缓冲区中的所有文本,与global命令类似(大多数命令行命令,如果不给它传递范围,则仅对当前行执行该命令)。如果您通过:w来指定地址:
:2w !node
“Vim”只使用第二行中的文本到node解释器中。
:w !node和:w! node形式上区别很小,但功能上相隔千里。使用:w !node,您是将当前缓冲区中的文本”写入”到外部命令node中。用:w! node,则您将强制保存文件并将其命名为”node”。
执行外部命令
您可以使用bang命令从Vim内部执行外部命令。语法为:
:!cmd
要以长格式查看当前目录的内容,请运行:
:!ls -ls
要终止在PID 3456上运行的进程,可以运行:
:!kill -9 3456
您可以在不离开Vim的情况下运行任何外部命令,因此您可以专注于自己的任务。
过滤文本
如果给!范围,则可用于过滤文本。假设您有:
hello vim
hello vim
让我们使用tr (translate)命令将当前行大写。运行:
:.!tr '[:lower:]' '[:upper:]'
结果:
HELLO VIM
hello vim
命令分解:
.!在当前行执行filter命令。!tr '[:lower:]' '[:upper:]'调用tr外部命令将所有小写字符替换为大写字符。
必须传递范围以运行外部命令作为过滤器。如果您尝试在没有.的情况下运行上述命令(:!tr '[:lower:]' '[:upper:]'),则会看到错误。
假设您需要使用awk命令删除两行的第二列:
:%!awk "{print $1}"
结果:
hello
hello
命令分解:
:%!在所有行(%)上执行filter命令。awk "{print $1}"仅打印匹配项的第一列。
您可以使用管道运算符(|)链接多个命令,就像在终端中一样。假设您有一个包含这些美味早餐的文件:
name price
chocolate pancake 10
buttermilk pancake 9
blueberry pancake 12
如果您需要根据价格对它们进行排序,并且仅以均匀的间距显示菜单,则可以运行:
:%!awk 'NR > 1' | sort -nk 3 | column -t
结果:
buttermilk pancake 9
chocolate pancake 10
blueberry pancake 12
命令分解:
:%!将过滤器应用于所有行(%)。awk 'NR > 1'仅从第二行开始显示文本。|链接下一个命令。sort -nk 3使用列3(k 3)中的值对数字进行排序(n)。column -t以均匀的间距组织文本。
普通模式命令
在普通模式下,Vim有一个过滤运算符(!)。如果您有以下问候:
hello vim
hola vim
bonjour vim
salve vim
要大写当前行和下面的行,可以运行:
!jtr '[a-z]' '[A-Z]'
命令分解:
!j运行常规命令过滤器运算符(!),目标是当前行及其下方的行。回想一下,因为它是普通模式运算符,所以适用语法规则”动词+名词”。tr '[a-z]' '[A-Z]'将小写字母替换为大写字母。
filter normal命令仅适用于至少一行以上的motion或至少一行以上的文本对象。如果您尝试运行!iwtr'[az]''[AZ]'(在内部单词上执行tr),您会发现它在整个行上都应用了tr命令,而不是光标所在的单词。
聪明地学习外部命令
Vim不是IDE。它是一种轻量级的模式编辑器,通过设计可以高度扩展。由于这种可扩展性,您可以轻松访问系统中的任何外部命令。这样,Vim离成为IDE仅一步之遥。有人说Unix系统是有史以来的第一个IDE。
Bang 命令的有用程度与您知道多少个外部命令相关。如果您的外部命令知识有限,请不要担心。我还有很多东西要学。以此作为持续学习的动力。每当您需要过滤文本时,请查看是否存在可以解决问题的外部命令。不必担心掌握所有的命令。只需学习完成当前任务所需的内容即可。
第15章 命令行模式
在前三章中,您已经学习了如何使用搜索命令(/, ?)、替换命令(:s)、全局命令(:g),以及外部命令(!)。这些都是命令行模式命令的一些例子。
在本章中,您将学习命令行模式的更多技巧。
进入和退出命令行模式
命令行模式本身也是一种模式,就像普通模式、输入模式、可视模式一样。在这种模式中,光标将转到屏幕底部,此时您可以输入不同的命令。
有 4 种进入命令行模式的方式:
- 搜索命令 (
/,?) - 命令行指令 (
:) - 外部命令 (
!)
您可以从正常模式或可视模式进入命令行模式。
若要离开命令行模式,您可以使用 <esc>、Ctrl-c、Ctrl-[。
有时其他资料可能会将”命令行指令”称为”Ex 命令”,将”外部命令”称为”过滤命令”或者”叹号运算符”。
重复上一个命令
您可以用 @: 来重复上一个命令行指令或外部命令。
如果您刚运行 :s/foo/bar/g,执行 @: 将重复该替换。如果您刚运行 :.!tr '[a-z]' '[A-Z]',执行 @: 将重复上一次外部命令转换过滤。
命令行模式快捷键
在命令行模式中,您可以使用 Left 或 Right 方向键,来左右移动一个字符。
如果需要移动一个单词,使用 Shift-Left 或 Shift-Right (在某些操作系统中,您需要使用 Ctrl 而不是 Shift)。
使用 Ctrl-b移动到该行的开始,使用 Ctrl-e移动到该行的结束。
和输入模式类似,在命令行模式中,有三种方法可以删除字符:
Ctrl-h 删除一个字符
Ctrl-w 删除一个单词
Ctrl-u 删除一整行
最后,如果您想像编辑文本文件一样来编辑命令,可以使用 Ctrl-f。
这样还可以查看过往的命令,并在这种”命令行编辑的普通模式”中编辑它们,同时还能按下 Enter 来运行它们。
寄存器和自动补全
当处于命令行模式时,您可以像在插入模式中一样使用 Ctrl-r 从Vim寄存器中插入文本。如果您在寄存器 a 中存储了字符串 “foo” ,您可以执行 Ctrl-r a 从寄存器a中插入该文本。任何在插入模式中您可以从寄存器中获取的内容,在命令行模式中您也可以获取。
另外,您也可以按 Ctrl-r Ctrl-w 获取当前光标下的单词(按 Ctrl-r Ctrl-A 获取当前光标下的词组)。还可以按 Ctrl-r Ctlr-l 获取当前光标所在行。按 Ctrl-r Ctrl-f 获取光标下的文件名。
您也可以对已存在的命令使用自动补全。要自动补全 echo 命令,当处于命令行模式时,首先输入 “ec”,接着按下 <Tab>,此时您应该能在左下角看到一些 “ec” 开头的 Vim 命令(例如:echo echoerr echohl echomsg econ)。按下 <Tab> 或 Ctrl-n 可以跳到下一个选项。按下 <Shift-Tab> 或 Ctrl-p 可以回到上一个选项。
一些命令行指令接受文件名作为参数。edit 就是一个例子,这时候您也可以使用自动补全。当输入 :e 后(不要忘记空格了),按下 <Tab>,Vim 将列出所有相关的文件名,这样您就可以进行选择而不必完整的输入它们。
历史记录窗口
您可以查看命令行指令和搜索项的历史记录(要确保在运行 vim --version 时,Vim 的编译选项中含有+cmdline_hist)。
运行 :his : 来查看命令行指令的历史记录:
## cmd History
2 e file1.txt
3 g/foo/d
4 s/foo/bar/g
Vim 列出了您运行的所有 : 命令。默认情况下,Vim 存储最后 50 个命令。运行 :set history=100 可以将 Vim 记住的条目总数更改为 100。
一个更有用的做法是使用命令行历史记录窗口,按q:将会打开一个可搜索、可编辑的历史记录窗口。假设按下q:后您有如下的表达式:
51 s/verylongsubstitutionpattern/pancake/g
52 his :
53 wq
如果您当前任务是执行 s/verylongsubstitutionpattern/donut/g(”pancake”换成了”donut”),为什么不复用 s/verylongsubstitutionpattern/pancake/g 呢?毕竟,两条命令唯一不同的是替换的单词,”donut” vs “pancake” ,所有其他的内容都是相同的。
当您运行 q:后,在历史记录中找到 s/verylongsubstitutionpattern/pancake/g(在这个环境中,您可以使用Vim导航),然后直接编辑它! 在历史记录窗口中将 “pancake” 改为 “donut” ,然后按 <Enter。Vim立刻执行 s/verylongsubstitutionpattern/donut/g 命令,超级方便!
类似地,运行 :his / 或 :his ? 可以查看搜索记录。要想打开您可以直接搜索和编辑的搜索历史记录窗口,您可以运行 q/ 和 q?。
要退出这个窗口,按 Ctrl-c, Ctrl-w c, 或输入 :quit。
更多命令行指令
Vim有几百个内置指令,要查看Vim的所有指令,执行 :h ex-cmd-index 或 :h :index。
聪明地学习命令行模式
对比其他三种模式,命令行模式就像是文本编辑中的瑞士军刀。寥举几例,您可以编辑文本、修改文件和执行命令。本章是命令行模式的零碎知识的集合。同时,Vim 模式的介绍也走向尾声。现在,您已经知道如何使用普通、输入、可视以及命令行模式,您可以比以往更快地使用 Vim 来编辑文本了。
是时候离开 Vim 模式,来了解如何使用 Vim 标记进行更快的导航了。
第16章 标签
快速转到任意定义处,是文本编辑中一个非常有用的特性。在本章中,您将学习如何使用 Vim 标签来做到这一点。
标签概述
假设有人给了您一个新的代码库:
one = One.new
one.donut
One?donut?呃,对于当时编写代码的开发者而言,这些代码的含义可能显而易见。问题是当时的开发者已经不在了,现在要由您来理解这些费解的代码。而跟随有One 和 donut定义的源代码,是帮助您理解的一个有效方法。
您可以使用fzf 或 grep来搜索它们,但这种情况下,但使用标签将更快。
把标签想象成地址簿:
Name Address
Iggy1 1234 Cool St, 11111
Iggy2 9876 Awesome Ave, 2222
当然,标签可不是存储着“姓名-地址”对,而是“定义-地址”对。
假设您在一个目录中有两个 Ruby 文件:
## one.rb
class One
def initialize
puts "Initialized"
end
def donut
puts "Bar"
end
end
以及
## two.rb
require './one'
one = One.new
one.donut
在普通模式下,您可以使用Ctrl-]跳转到定义。在two.rb中,转到one.donut所在行,将光标移到donut处,按下Ctrl-]。
哦豁,Vim 找不到标签文件,您需要先生成它。
标签生成器
现代 Vim 不自带标签生成器,您需要额外下载它。有几个选项可供选择:
- ctags = 仅用于 C,基本随处可见。
- exuberant ctags = 最流行的标签生成器之一,支持许多语言。
- universal ctags = 和 exuberant ctags 类似,但比它更新。
- etags = 用于 Emacs,嗯……
- JTags = Java
- ptags.py = Python
- ptags = Perl
- gnatxref = Ada
如果您查看 Vim 在线教程,您会发现许多都会推荐 exuberant ctags,它支持 41 种编程语言,我用过它,挺不错的。但自2009年以来一直没有维护,因此 Universal ctags 更好些,它和 exuberant ctags 相似,并仍在维护。
我不打算详细介绍如何安装 Universal ctags,您可以在 universal ctags 仓库了解更多说明。
假设您已经安装好了ctags,接下来,生成一个基本的标签文件。运行:
ctags -R .
R 选项告诉 ctags 从当前位置 (.) 递归扫描文件。稍后,您应该在当前文件夹看到一个tags 文件,里面您将看到类似这样的内容:
!_TAG_FILE_FORMAT 2 /extended format; --format=1 will not append ;" to lines/
!_TAG_FILE_SORTED 1 /0=unsorted, 1=sorted, 2=foldcase/
!_TAG_OUTPUT_FILESEP slash /slash or backslash/
!_TAG_OUTPUT_MODE u-ctags /u-ctags or e-ctags/
!_TAG_PATTERN_LENGTH_LIMIT 96 /0 for no limit/
!_TAG_PROGRAM_AUTHOR Universal Ctags Team //
!_TAG_PROGRAM_NAME Universal Ctags /Derived from Exuberant Ctags/
!_TAG_PROGRAM_URL <https://ctags.io/> /official site/
!_TAG_PROGRAM_VERSION 0.0.0 /b43eb39/
One one.rb /^class One$/;" c
donut one.rb /^ def donut$/;" f class:One
initialize one.rb /^ def initialize$/;" f class:One
根据 Vim 设置和 ctag 生成器的不同,您的tags 文件可能会有些不同。一个标签文件由两部分组成:标签元数据和标签列表。那些标签元数据 (!TAG_FILE...) 通常由 ctags 生成器控制。这里我不打算介绍它们,您可以随意查阅文档。标签列表是一个由所有定义组成的列表,由ctags建立索引。
现在回到 two.rb,将光标移至 donut,再输入Ctrl-],Vim 将带您转到 one.rb 文件里def donut 所在的行上。成功啦!但 Vim 怎么做到的呢?
解剖标签文件
来看看donut 标签项:
donut one.rb /^ def donut$/;" f class:One
上面的标签项由四个部分组成:一个tagname、一个tagfile、一个tagaddress,以及标签选项。
donut是tagname。当光标在 “donut” 时,Vim 搜索标签文件里含有 “donut” 字符串的一行。one.rb是tagfile。Vim 会搜寻one.rb文件。/^ def donut$/是tagaddress。/.../是模式指示器。^代表一行中第一个元素,后面跟着两个空格,然后是def donut字符串,最后$代表一行中最后一个元素。f class:One是标签选项,它告诉 Vim,donut是一种函数 (f),并且是One类的一部分。
再看看另一个标签项:
One one.rb /^class One$/;" c
这一行和 donut也是一样的:
One是tagname。注意,对于标签,第一次扫描区分大小写。如果列表中有One和one, Vim 会优先考虑One而不是one。one.rb是tagfile。Vim 会搜寻one.rb文件。/^class One$/是tagaddress。Vim 会查找以class开头 (^) 、以One结尾 ($) 的行。c是可用标签选项之一。由于One是一个 ruby 类而不是过程,因此被标签为c。
标签文件的内容可能不尽相同,根据您使用的标签生成器而定。但至少,标签文件必须具有以下格式之一:
1. {tagname} {TAB} {tagfile} {TAB} {tagaddress}
2. {tagname} {TAB} {tagfile} {TAB} {tagaddress} {term} {field} ..
标签文件
您知道,在运行 ctags -R . 后,一个新 tags 文件会被创建。但是,Vim 是如何知道在哪儿查找标签文件的呢?
如果运行 :set tags?,您可能会看见 tags=./tags,tags(根据您的 Vim 设置,内容可能有所不同)。对于 ./tags,Vim 会在当前文件所在路径查找所有标签;对于 tags,Vim 会在当前目录(您的项目根路径)中查找。
此外,对于 ./tags,Vim 会在当前文件所在路径内查找一个标签文件,无论它被嵌套得有多深。接下来,Vim 会在当前目录(项目根路径)查找。Vim 在找到第一个匹配项后会停止搜索。
如果您的 'tags' 文件是 tags=./tags,tags,/user/iggy/mytags/tags,那么 Vim 在搜索完 ./tags 和 tags 目录后,还会在 /user/iggy/mytags 目录内查找。所以您可以分开存放标签文件,不必将它们置于项目文件夹中。
要添加标签文件位置,只需要运行:
:set tags+=path/to/my/tags/file
为大型项目生成标签:
如果您尝试在大型项目中运行 ctag,则可能需要很长时间,因为 Vim 也会查看每个嵌套目录。如果您是 Javascript 开发者,您会知道 node_modules 非常大。假设您有五个子项目,每个都包含自己的 node_modules 目录。一旦运行 ctags -R .,ctags 将尝试扫描这5个 node_modules。但您可能不需要为 node_modules 运行 ctag。
如果要排除 node_modules 后执行 ctags,可以运行:
ctags -R --exclude=node_modules .
这次应该只需要不到一秒钟的时间。另外,您还可以多次使用 exclude 选项:
ctags -R --exclude=.git --exclude=vendor --exclude=node_modules --exclude=db --exclude=log .
标签导航
仅使用 Ctrl-] 也挺好,但我们还可以多学几个技巧。其实,标签跳转键 Ctrl-] 还有命令行模式::tag my-tag。如果您运行:
:tag donut
Vim 就会跳转至 donut 方法,就像在 “donut” 字符串上按 Ctrl-] 一样。您还可以使用 <Tab> 来自动补全参数:
:tag d<Tab>
Vim 会列出所有以 “d” 开头的标签。对于上面的命令,结果则是 “donut”。
在实际项目中,您可能会遇到多个同名的方法。我们来更新下这两个文件。先是 one.rb:
## one.rb
class One
def initialize
puts "Initialized"
end
def donut
puts "one donut"
end
def pancake
puts "one pancake"
end
end
然后 two.rb:
## two.rb
require './one.rb'
def pancake
"Two pancakes"
end
one = One.new
one.donut
puts pancake
由于新添加了一些过程,因此编写完代码后,不要忘记运行 ctags -R .。现在,您有了两个 pancake 过程。如果您在 two.rb 内按下 Ctrl-],会发生什么呢?
Vim 会跳转到 two.rb 内的 def pancake,而不是 one.rb 的 def pancake。这是因为 Vim 认为 two.rb 内部的 pancake 过程比其他的pancake 过程具有更高优先级。
标签优先级
并非所有的标签都有着相同的地位。一些标签有着更高的优先级。如果有重复的标签项,Vim 会检查关键词的优先级。顺序是:
- 当前文件中完全匹配的静态标签。
- 当前文件中完全匹配的全局标签。
- 其他文件中完全匹配的全局标签。
- 其他文件中完全匹配的静态标签。
- 当前文件中不区分大小写匹配的静态标签。
- 当前文件中不区分大小写匹配的全局标签。
- 其他文件中区分大小写匹配的全局标签。
- 当前文件中不区分大小写匹配的静态标签。
根据优先级列表,Vim 会对在同一个文件上找到的精确匹配项进行优先级排序。这就是为什么 Vim 会选择 two.rb 里的 pancake 过程而不是 one.rb 里的。但是,上述优先级列表有些例外,取决于您的'tagcase'、'ignorecase'、'smartcase' 设置。我不打算介绍它们,您可以自行查阅 :h tag-priority。
选择性跳转标签
如果可以选择要跳转到哪个标签,而不是始终转到优先级最高的,那就太好了。因为您可能想跳转到 one.rb 里的 pancake 方法,而不是 two.rb 里的。现在您可以使用 :tselect 做到它!运行:
:tselect pancake
您可以在屏幕底部看到:
## pri kind tag file
1 F C f pancake two.rb
def pancake
2 F f pancake one.rb
class:One
def pancake
如果输入2 后再 <Return>,Vim 将跳转到 one.rb 里的pancake 过程。如果输入1 后再 <Return>,Vim 将跳转到 two.rb 里的。
注意pri 列,第一个匹配中该列是F C,第二个匹配中则是F。这就是 Vim 用来确定标签优先级的凭据。F C表示在当前 (C) 文件中完全匹配 (F) 的全局标签。F 表示仅完全匹配 (F) 的全局标签。F C 的优先级永远比 F 高。(译注:F是Fully-matched,C是Current file)
如果运行:tselect donut,即使只有一个标签可选,Vim 也会提示您选择跳转到哪一个。有没有什么方法可以让 Vim 仅在有多个匹配项时才提示标签列表,而只找到一个标签时就立即跳转呢?
当然!Vim 有一个 :tjump 方法。运行:
:tjump donut
Vim 将立即跳转到 one.rb 里的donut 过程,就像在运行 :tag donut 一样。现在试试:
:tjump pancake
Vim 将提示您从标签选项中选择一个,就像在运行:tselect pancake。tjump 能两全其美。
tjump 在普通模式下有一个快捷键:g Ctrl-]。我个人喜欢g Ctrl-]胜过 Ctrl-]。
标签的自动补全
标签能有助于自动补全。回想下第6章“插入模式”,您可以使用 Ctrl-x 子模式来进行各式自动补全。其中有一个我没有提到过的自动补全子模式便是 Ctrl-]。如果您在插入模式中输入Ctrl-x Ctrl-],Vim 将使用标签文件来自动补全。
在插入模式下输入Ctrl-x Ctrl-],您会看到:
One
donut
initialize
pancake
标签堆栈
Vim 维持着一个标签堆栈,上面记录着所有您从哪儿来、跳哪儿去的标签列表。使用 :tags 可以看到这个堆栈。如果您首先跳转到pancake,紧接着是donut,此时运行:tags,您将看到:
# TO tag FROM line in file/text
1 1 pancake 10 ch16_tags/two.rb
2 1 donut 9 ch16_tags/two.rb
>
注意上面的 > 符号,它代表着您当前在堆栈中的位置。要“弹出”堆栈,从而回到上一次的状态,您可以运行:pop。试试它,再运行:tags看看:
# TO tag FROM line in file/text
1 1 pancake 10 puts pancake
> 2 1 donut 9 one.donut
注意现在 > 符号位于 donut 所在的第二行了。再 pop 一次,然后运行:tags:
# TO tag FROM line in file/text
> 1 1 pancake 10 puts pancake
2 1 donut 9 one.donut
在普通模式下,您可以按下 Ctrl-t 来达到和 :pop 一样的效果。
自动生成标签
Vim 标签最大的缺点之一是,每当进行重大改变时,您需要重新生成标签文件。如果您将pancake 过程重命名为 waffle,标签文件不知道 pancake 被重命名了,标签列表仍旧存储着 pancake 过程。运行ctags -R . 可以创建更新的标签文件,但这可能会很缓慢。
幸运的是,有几种可以自动生成标签的方法。这一小节不打算介绍一个简单明了的过程,而是提出一些想法,以便您可以扩展它们。
在保存时生成标签
Vim 有一个自动命令 (autocmd) 方法,可以在触发事件时执行任意命令。您可以使用这个方法,以便在每次保存时生成标签。运行:
:autocmd BufWritePost *.rb silent !ctags -R .
上面命令的分解如下:
autocmd是 Vim 的自动命令方法,它接受一个事件名称、文件和一个命令。BufWritePost是保存缓冲区时的一个事件。每次保存文件时将触发一次BufWritePost事件。.rb是 ruby (rb) 文件的一种文件模式。silent是您传递的命令的一部分。如果不输入它,每次触发自动命令时,Vim 都会提示press ENTER or type command to continue。!ctags -R .是要执行的命令。回想一下,!cmd从 Vim 内部执行终端命令。
现在,每次您保存一个 ruby 文件时,Vim 都会运行ctags -R .。
使用插件
有几种插件可以自动生成 ctags:
我使用 vim-gutentags。它的使用方法很简单,而且装上就可以直接使用。
Ctags 以及 Git 钩子
Tim Pope 是一个写了很多非常棒的 Vim 插件的作者,他写了一篇博客,建议使用 git 钩子。可以看一看。
聪明地学习标签
只要配置得当,标签是非常有用的。假设在一个新的代码库中,您想要搞清楚 functionFood 干了什么,您可以通过跳转到它的定义来搞懂它们。在那儿可以看到,它又调用了 functionBreakfast。继续跟踪,发现还调用了 functionPancake。现在您明白了,函数调用路径图长这样:
functionFood -> functionBreakfast -> functionPancake
进一步可以知道,这段代码和早餐吃煎饼有关。
现在您已经知道如何使用标签,通过 :h tags 可以学习更多有关标签的知识。接下来让我们一起来探索另一个功能:折叠。
第17章 折叠
在阅读文件时,经常会有一些不相关的文本会妨碍您理解。使用 Vim 折叠可以隐藏这些不必要的信息。
本章中,您将学习如何使用不同的折叠方法。
手动折叠
想象您正在折叠一张纸来覆盖一些文本,实际的文本不会消失,它仍在那儿。Vim 折叠的工作方式与此相同,它折叠一段文本,在显示时会隐藏起来,但实际上并不会真的删除它。
折叠操作符是z。(折叠纸张时,它看起来也像字母 “z”)。
假设有如下文本:
Fold me
Hold me
把光标放在第一行,输入 zfj。Vim 将这两行折叠成一行,同时会看到类似消息:
+-- 2 lines: Fold me -----
上面的命令分解如下:
zf是折叠操作符。j是用于折叠操作符的动作。
您可以使用 zo 打开/展开已折叠文本,使用 zc 关闭/收缩文本。
折叠是一个操作符,所以它遵循语法规则(动词+名词)。您可以在折叠运算符后,加上一个动作(motion)或文本对象。例如,使用 zfip 可以折叠内部段落;使用 zfG 可以折叠至文件末尾;使用 zfa{ 可以折叠 { 和 } 之间的文本。
您可以在可视模式下进行折叠。高亮您想要折叠的区域后 (v, V, 或 Ctrl-v),再输入 zf 即可。
您也可以在命令行模式下,使用 :fold 命令执行一次折叠。若要折叠当前行及紧随其后的第二行,可以运行:
:,+1fold
,+1 是要折叠的范围。如果不传递范围参数,默认当前行。+1 是代表下一行的范围指示器。运行 :5,10fold 可以折叠第5至10行。运行 :,$fold 可以折叠当前行至文件末尾。
还有许多其他折叠和展开的命令。我发现他们实在太多,以至于在刚起步时很难记住。最有用的一些命令是:
zR展开所有折叠。zM收缩所有折叠。za切换折叠状态。
zR 和 zM 可用于任意行上,但 za 仅能用于已折叠/未折叠的行上。输入 :h fold-commands 可查阅更多有关折叠的指令。
不同的折叠方法
以上部分涵盖了 Vim 手动折叠的内容。实际上,Vim 有六种不同的折叠方法:
- 手动折叠
- 缩进折叠
- 表达式折叠
- 语法折叠
- 差异折叠
- 标志折叠
运行 :set foldmethod? 可查看您当前正在使用哪一种折叠方式。默认情况下,Vim 使用手动方式。
在本章的剩余部分,您将学习其他五种折叠方法。让我们从缩进折叠开始。
缩进折叠
要使用缩进折叠,需要将 'foldmethod' 选项更改为缩进:
:set foldmethod=indent
假设有如下文本:
One
Two
Two again
运行 :set foldmethod=indent 后将看到:
One
+-- 2 lines: Two -----
使用缩进折叠后,Vim 将会查看每行的开头有多少空格,并将它与 'shiftwidth' 选项进行比较,以此来决定该行可折叠性。'shiftwidth' 返回每次缩进所需的空格数。如果运行:
:set shiftwidth?
Vim 的默认 'shiftwidth' 值为2。对于上面的文本而言,”Two” 和 “Two again” 的开头都有两个空格。当 Vim 看到了空格数 且 'shiftwidth'值都为2时,Vim 认为该行的缩进折叠级别为1。
假设这次文本开头只有一个空格:
One
Two
Two again
运行 :set foldmethod=indent 后,Vim 不再折叠已缩进的行了,因为这些行没有足够的空格。1个空格不会被视作一个缩进。然而,当您改变 'shiftwidth' 的值为1后:
:set shiftwidth=1
文本现在可以折叠了!现在一个空格将被视为一个缩进。
现在,我们将 'shiftwidth' 以及文本开头的空格数都重新恢复为2后,另外添加一些内容:
One
Two
Two again
Three
Three again
运行折叠命令 (zM) 后可以看到:
One
+-- 4 lines: Two -----
展开已折叠的行 (zR),接着移动光标至 “Three”,然后切换文本的折叠状态 (za):
One
Two
Two again
+-- 2 lines: Three -----
这是啥?叠中叠?
是的,您可以嵌套折叠。文本 “Two” 和 “Two again” 的折叠级别都为1,文本 “Three” 和 “Three again” 的折叠级别都为2。如果在一段可折叠文本中,具有另一段折叠级别更高的可折叠文本,则可以具有多个折叠层。
表达式折叠
表达式折叠允许您定义要匹配折叠的表达式。定义折叠表达式后,Vim 会计算每行的 'foldexpr' 值。这是必须配置的变量,它要返回适当的值。如果返回 0,则不折叠行。如果它返回 1,则该行的折叠级别为 1。如果它返回 2,则该线的折叠级别为 2。除了整数外还有其他的值,但我不打算介绍它们。如果你好奇,可以查阅:h fold-expr。
首先,更改折叠方法:
:set foldmethod=expr
假设您有一份早餐食品列表,并且想要折叠所有以 “p” 开头的早餐项:
donut
pancake
pop-tarts
protein bar
salmon
scrambled eggs
其次,更改 foldexpr 为捕获以 “p” 开头的表达式:
:set foldexpr=getline(v:lnum)[0]==\\"p\\"
这表达式看起来有点吓人。我们来分解下:
:set foldexpr设置'foldexpr'为自定义表达式。getline()是 Vim 脚本的一个函数,它返回指定行的内容。如运行:echo getline(5)可以获取第5行的内容。v:lnum是 Vim'foldexpr'表达式的特殊变量。Vim 在扫描每一行时,都会将行号存储至v:lnum变量。在第5行,v:lnum值为5。在第10行,v:lnum值为10。[0]处于getline(v:lnum)[0]语境时,代表每一行的第一个字符。Vim 在扫描某一行时,getline(v:lnum)返回该行的内容,而getline(v:lnum)[0]则返回这一行的第一个字符。例如,我们早餐食品列表的第一行是 “donut”,则getline(v:lnum)[0]返回 “d”;列表的第二行是 “pancake”,则getline(v:lnum)[0]返回 “p”。==\\"p\\"是等式表达式的后半部分,它检查刚才表达式的计算结果是否等于 “p”。如果是,则返回1,否则返回0。在 Vim 的世界里,1代表真,0代表假。所以,那些以 “p” 开头的行,表达式都会返回1。回想一下本节的开始,如果'foldexpr'的值为1,则折叠级别为1。
在运行这个表达式后,您将看到:
donut
+-- 3 lines: pancake -----
salmon
scrambled eggs
语法折叠
语法折叠是由Vim的语法高亮决定的。如果您使用了语法高亮插件,比如vim-polyglot,那么装上插件就可以直接使用语法折叠。仅仅需要将foldmethod选项改为 syntax。
:set foldmethod=syntax
假设您正在编辑一个JavaScript文件,而且您已经装好了 vim-polyglot 插件。如果您有以下文本:
const nums = [
one,
two,
three,
four
]
上述文本将会使用语法折叠折起来。当您为某个特定语言(位于 syntax/ 目录中的语言即是典型例子)定义了语法高亮,您可以添加一个 fold 属性,使它支持折叠。下面是 vim-polyglot 中JavaScript语法文件中的一个片段。注意最后的 fold 关键字。
syntax region jsBracket matchgroup=jsBrackets start=/\[/ end=/\]/ contains=@jsExpression,jsSpreadExpression extend fold
本书不会详细介绍 syntax 功能。如果您感兴趣,可以查阅 :h syntax.txt。
差异折叠
Vim 可以对多个文件进行差异比较。
如果您有 file1.txt:
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
以及 file2.txt:
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
emacs is ok
运行 vimdiff file1.txt file2.txt:
+-- 3 lines: vim is awesome -----
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
vim is awesome
[vim is awesome] / [emacs is ok]
Vim 会自动折叠一些相同的行。运行 vimdiff 命令时,Vim 会自动使用 foldmethod=diff。此时如果运行 :set foldmethod?,它将返回 diff。
标志折叠
要使用标志折叠,请运行:
:set foldmethod=marker
假设有如下文本:
Hello
}
输入 zM 后会看到:
hello
+-- 4 lines: -----
Vim 将 } 视为折叠指示器,并折叠其中的内容。使用标志折叠时,Vim 会寻找由 'foldmarker' 选项定义的特殊标志,并标记折叠区域。要查看 Vim 使用的标志,请运行:
:set foldmarker?
默认情况下,Vim 把 } 作为指示器。如果您想将指示器更改为其他诸如 “coffee1” 和 “coffee2” 的字符串,可以运行:
:set foldmarker=coffee1,coffee2
假设有如下文本:
hello
coffee1
world
vim
coffee2
现在,Vim 将使用 coffee1 和 coffee2 作为新折叠标志。注意,指示器必须是文本字符串,不能是正则表达式。
持久化折叠
当关闭 Vim 会话后,您将失去所有的折叠信息。假设您有 count.txt 文件:
one
two
three
four
five
手动从第三行开始往下折叠 (:3,$fold):
one
two
+-- 3 lines: three ---
当您退出 Vim 再重新打开 count.txt 后,这些折叠都不见了!
要在折叠后保留它们,可以运行:
:mkview
当打开 count.txt 后,运行:
:loadview
您的折叠信息都被保留下来了。然而,您需要手动运行 mkview 和 loadview。我知道,终有一日,我会忘记运行 mkview 就关闭文件了,接着便会丢失所有折叠信息。能不能自动实现这个呢?
当然能!要在关闭 .txt 文件时自动运行 mkview,以及在打开 .txt 文件后自动运行 loadview,将下列内容添加至您的 vimrc:
autocmd BufWinLeave *.txt mkview
autocmd BufWinEnter *.txt silent loadview
在上一章您已经见过 autocmd 了,它用于在事件触发时执行一条命令。这里的两个事件是:
BufWinLeave从窗口中删除缓冲时。BufWinEnter在窗口中加载缓冲时。
现在,即使您在 .txt 文件内折叠内容后直接退出 Vim,下次再打开该文件时,您的折叠信息都能自动恢复。
默认情况下,当运行 mkview 时,Vim将折叠信息保存在~/.vim/view (Unix 系统)。您可以查阅 :h 'viewdir' 来了解更多信息。
聪明地学习折叠
当我刚开始使用 Vim 时, 我会跳过学习 Vim 折叠,因为我觉得它不太实用。然而,随着我码龄的增长,我越发觉得折叠功能大有用处。得当地使用折叠功能,文本结构可以更加清晰,犹如一本书籍的目录。
当您学习折叠时,请从手动折叠开始,因为它可以随学随用。然后逐渐学习不同的技巧来使用缩进和标志折叠。最后,学习如何使用语法和表达式折叠。您甚至可以使用后两个来编写您自己的 Vim 插件。
第18章 Git
Vim 和 Git 是两种实现不同功能的伟大工具。Vim 用于文本编辑,Git 用于版本控制。
在本章中,您将学习如何将 Vim 和 Git 集成在一起。
差异比较
在上一章中,您看到了如何运行 vimdiff 命令以显示多个文件之间的差异。
假设您有两个文件,file1.txt 和 file2.txt。
file1.txt 的内容如下:
pancakes
waffles
apples
milk
apple juice
yogurt
file2.txt 的内容如下:
pancakes
waffles
oranges
milk
orange juice
yogurt
若要查看两个文件之间的差异,请运行:
vimdiff file1.txt file2.txt
或者也可以运行:
vim -d file1.txt file2.txt
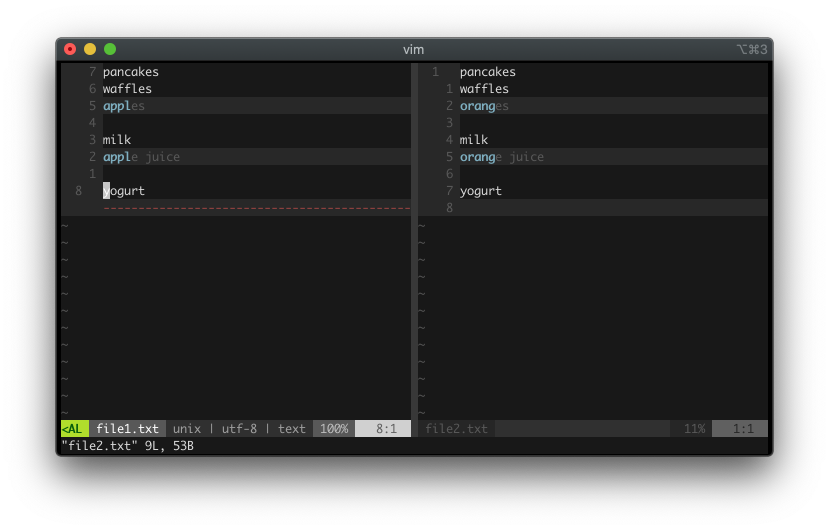
vimdiff 并排显示两个缓冲区。左边是 file1.txt,右边是 file2.txt。不同的两行(apples 和 oranges)会被高亮显示。
假设您要使第二个缓冲区相应位置变成 apples,而不是 oranges。若想从 file1.txt 传输您当前位置(当前您在 file1.txt)的内容到 file2.txt,首先使用 ]c 跳转到下一处差异(使用 [c 可跳回上一处差异),现在光标应该在 apples 上了。接着运行 :diffput。此时,这两个文件都是 apples 了。
如果您想从另一个缓冲区(orange juice,file2.txt)传输文本来替代当前缓冲区(apple juice,file1.txt),让您的光标仍然位于 file1.txt 的窗口中,首先使用 ]c 跳转至下一处差异,此时光标应该在 apple juice 上。接着运行 :diffget 获取另一个缓冲区的 orange juice 来替代当前缓冲区中的 apple juice。
:diffput 将文本从当前缓冲区 输出 到另一个缓冲区。:diffget 从另一个缓冲区 获取 文本到当前缓冲区。
如果有多个缓冲区,可以运行 :diffput fileN.txt 和 :diffget fileN.txt 来指定目标缓冲区 fileN。
使用 Vim 作为合并工具
“我非常喜欢解决合并冲突。” ——佚名
我不知道有谁喜欢解决合并冲突,但总之,合并冲突是无法避免的。在本节中,您将学习如何利用 Vim 作为解决合并冲突的工具。
首先,运行下列命令来将默认合并工具更改为 vimdiff:
git config merge.tool vimdiff
git config merge.conflictstyle diff3
git config mergetool.prompt false
或者您也可以直接修改 ~/.gitconfig(默认情况下,它应该处于根目录中,但您的可能在不同的位置)。上面的命令应该会将您的 gitconfig 改成如下设置的样子,如果您还没有运行上面的命令,您也可以手动更改您的 gitconfig。
[core]
editor = vim
[merge]
tool = vimdiff
conflictstyle = diff3
[difftool]
prompt = false
让我们创建一个假的合并冲突来测试一下。首先创建一个目录 /food,并初始化 git 仓库:
git init
添加 breakfast.txt 文件,内容为:
pancakes
waffles
oranges
添加文件并提交它:
git add .
git commit -m "Initial breakfast commit"
接着,创建一个新分支 apples:
git checkout -b apples
更改 breakfast.txt 文件为:
pancakes
waffles
apples
保存文件,添加并提交更改:
git add .
git commit -m "Apples not oranges"
真棒!现在 master 分支有 oranges,而 apples 分支有 apples。接着回到 master 分支:
git checkout master
在 breakfast.txt 文件中,您应该能看到原来的文本 oranges。接着将它改成 grapes,因为它是现在的应季水果:
pancakes
waffles
grapes
保存、添加、提交:
git add .
git commit -m "Grapes not oranges"
嚯!这么多步骤!现在准备要将 apples 分支合并进 master 分支了:
git merge apples
您应该会看到如下错误:
Auto-merging breakfast.txt
CONFLICT (content): Merge conflict in breakfast.txt
Automatic merge failed; fix conflicts and then commit the result.
没错,一个冲突!现在一起来用一下新配置的 mergetool 来解决冲突吧!运行:
git mergetool
Vim 显示了四个窗口。注意一下顶部三个:
LOCAL包含了grapes。这是“本地”中的变化,也是您要合并的内容。BASE包含了oranges。这是LOCAL和REMOTE的共同祖先,用于比较它们之间的分歧。REMOTE包含了apples。这是要被合并的内容。
底部窗口(也即第四个窗口),您能看到:
pancakes
waffles
<<<<<<< HEAD
grapes
||||||| db63958
oranges
=======
apples
>>>>>>> apples
第四个窗口包含了合并冲突文本。有了这步设置,就能更轻松看到哪个环境发生了什么变化。您可以同时查看 LOCAL、BASE 和 REMOTE 的内容。
您的光标应该在第四个窗口的高亮区域。再运行 :diffget LOCAL,就可以获取来自 LOCAL 的改变(grapes)。同样,运行 :diffget BASE 可以获取来自 BASE 的改变(oranges),而运行 :diffget REMOTE 可以获取来自 REMOTE 的改变(apples)。
在这个例子中,我们试着获取来自 LOCAL 的改变。运行 :diffget LO(LOCAL 的简写),第四个窗口变成了 grapes。完成后,就可以保存并退出所有文件(:wqall)了。还不错吧?
稍加留意您会发现,现在多了一个 breakfast.txt.orig 文件。这是 Git 防止事与愿违而创建的备份文件。如果您不希望 Git 在合并期间创建备份文件,可以运行:
git config --global mergetool.keepBackup false
在 Vim 中使用 Git
Vim 本身没有集成 Git,要在 Vim 中执行 Git 命令,一种方法是在命令行模式中使用 ! 叹号运算符。
使用 ! 可以运行任何 Git 命令:
:!git status
:!git commit
:!git diff
:!git push origin master
您还可以使用 Vim 的特殊字符 % (当前缓冲区) 或 # (其他缓冲区):
:!git add % " git add current file
:!git checkout # " git checkout the other file
这里有一个Vim技巧,您可以用来添加不同Vim窗口中的多个文件,运行:
windo !git add %
然后提交:
:!git commit "添加了Vim窗口中的所有文件,酷"
windo命令是VIm的 “do” 命令其中之一,类似于您前面看到的 argdo 。windo 将命令执行在每一个窗口中。
插件
这里有很多提供git支持的Vim插件。以下是 Vim 中较流行的 Git 相关插件列表(您读到这篇文章时可能又有更多):
其中最流行的是 vim-fugitive。本章的剩余部分,我将使用此插件来介绍几个 git 工作流。
Vim-Fugitive
vim-fugitive 插件允许您在不离开 Vim 编辑器的情况下运行 git 命令行界面。您会发现,有些命令在 Vim 内部执行时会更好。
开始前,请先使用 Vim 插件管理器(vim-plug、vundle、dein.vim 等)安装 vim-fugitive。
Git Status
当您不带参数地运行 :Git 命令时,vim-fugitive 将显示一个 git 概要窗口,它显示了未跟踪、未暂存和已暂存的文件。在此 “git status” 模式下,您可以做一些操作:
Ctrl-n/Ctrl-p转到下一个 / 上一个文件。-暂存或取消暂存光标处的文件。s暂存光标处的文件。u取消暂存光标处的文件。>/<内联显示或隐藏光标处文件的差异变化。
查阅 :h fugitive-staging-maps 可获得更多信息。
Git Blame
在当前文件运行 :Git blame 命令,vim-fugitive 可以显示一个拆分的问责窗口。这有助于追踪那些 BUG 是谁写的,接着就可以冲他/她怒吼(开个玩笑)。
在 "git blame" 模式下您可以做:
q关闭问责窗口。A调整作者列大小。C调整提交列大小。D调整日期/时间列大小。
查阅 :h :Git_blame 可获得更多信息。
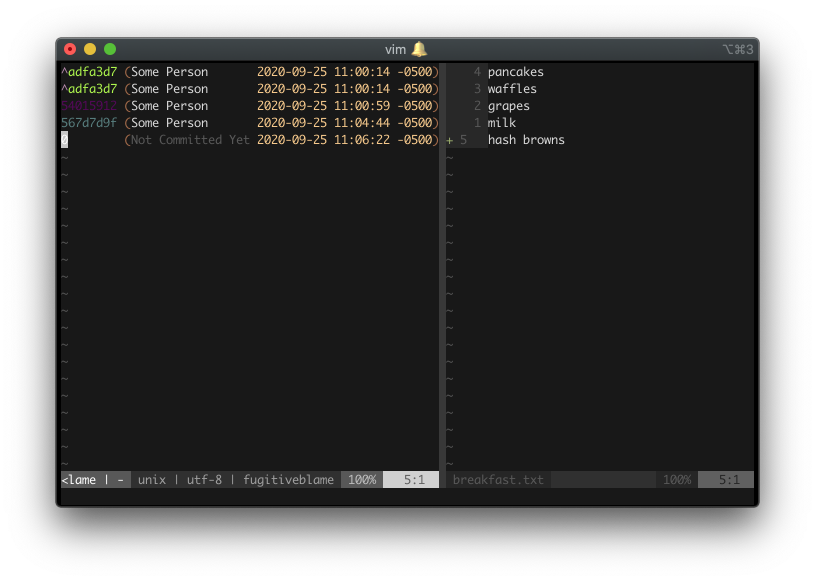
Gdiffsplit
当您运行 :Gdiffsplit 命令后,vim-fugitive 会执行 vimdiff,比对索引或工作树中的版本与当前文件最新更改的区别。如果运行 :Gdiffsplit <commit>,vim-fugitive 则会根据 <commit> 中的版本来执行 vimdiff。
由于您处于 vimdiff 模式中,因此您可以使用 :diffput 和 :diffget 来 获取 或 输出 差异。
Gwrite 和 Gread
当您在更改文件后运行 :Gwrite 命令,vim-fugitive 将暂存更改,就像运行 git add <current-file> 一样。
当您在更改文件后运行 :Gread 命令,vim-fugitive 会将文件还原至更改前的状态,就像运行 git checkout <current-file> 一样。使用 :Gread 还有一个好处是操作可撤销。如果在运行 :Gread 后您改变主意,想要保留原来的更改,您只需要撤消(u),Vim 将撤回 :Gread 操作。要换作是在命令行中运行 git checkout <current-file>,就完成不了这种操作了。
Gclog
当您运行 :Gclog 命令时,vim-fugitive 将显示提交历史记录,就像运行 git log 命令一样。Vim-fugitive 使用 Vim 的 quickfix 来完成此任务,因此您可以使用 :cnext 和 :cprevious 来遍历下一个或上一个日志信息。您还可以使用 :copen 和 :cclose 打开或关闭日志列表。
在 "git log" 模式中,您可以做两件事:
- 查看树。
- 访问父级(上一个提交)。
您可以像 git log 命令一样,传递参数给 :Gclog 命令。如果您项目的提交历史记录很长,只想看最后三个提交,则可以运行 :Gclog -3。如果需要根据提交日期来筛选记录,可以运行类似 :Gclog --after="January 1" --before="March 14" 的命令。
Vim-Fugitive 的更多功能
以上只是寥寥几个 vim-fugitive 功能的例子,您可以查阅 :h fugitive.txt 来了解更多有关 vim-fugitive 的信息。大多数流行的 git 命令可能都有 vim-fugitive 的优化版本,您只需在文档中查找它们。
如果您处于 vim-fugitive 的“特殊模式”(如 :Git 或 :Git blame 模式)中,按下 g? 可以了解当前有哪些可用的快捷键,Vim-fugitive 将为您所处的模式显示相应的 :help 窗口。棒极了!
聪明地学习 Vim 和 Git
每个人都有不同的 git 工作流,可能 vim-fugitive 非常合适您的工作流(也可能不适合)。总之,我强烈建议您试试上面列出的所有插件。可能还有一些其他的我没有列出来,都可以去试一试。
要让Vim-git的集成工作得更好,一个显而易见的办法就是去深入了解git。Git 本身是一个很庞大的主题,我只向您展示了它其中很小的一部分。好了,接下来谈谈如何使用 Vim 编译您的代码。
第19章 编译
编译是许多编程语言的重要主题。在本章中,您将学习如何在 Vim 中编译。此外,您将看到如何利用好 Vim 的 :make 命令。
从命令行编译
您可以使用叹号运算符(!)进行编译。如果您需要使用 g++ 来编译 .cpp 文件,可以运行:
:!g++ hello.cpp -o hello
但要每次手动指定文件名和输出文件名会非常繁琐和容易出错。而 makefile 是条可行之路。
Make命令
Vim 有运行 makefile 的 :make 命令。当您运行它时,Vim 会在当前目录查找 makefile 并执行它。
在当前目录创建一个文件名为 makefile ,然后添加下列内容:
all:
echo "Hello all"
foo:
echo "Hello foo"
list_pls:
ls
在 Vim 中运行:
:make
Vim 执行它的方式与从终端运行它的方式相同。:make 命令也接受终端中 make 命令的参数。运行:
:make foo
" Outputs "Hello foo"
:make list_pls
" Outputs the ls command result
如果命令执行异常,:make 命令将使用 Vim 的 quickfix 来存储这些错误。现在试着运行一个不存在的目标:
:make dontexist
您应该会看到该命令执行错误。运行 quickfix 命令 :copen 可以打开 quickfix 窗口来查看该错误:
|| make: *** No rule to make target `dontexist'. Stop.
使用 Make 编译
让我们使用 makefile 来编译一个基本的 .cpp 程序。首先创建一个 hello.cpp 文件:
#include <iostream>
int main() {
std::cout << "Hello!\n";
return 0;
}
然后,更新 makefile 来编译和运行 .cpp 文件:
all:
echo "build, run"
build:
g++ hello.cpp -o hello
run:
./hello
现在运行:
:make build
g++ 将编译 ./hello.cpp 并且生成 ./hello。接着运行:
:make run
您应该会看到终端上打印出了 "Hello!"。
不同的Make程序
当您运行 :make 时,Vim 实际上会执行 makeprg 选项所设置的任何命令,您可以运行 :set makeprg? 来查看它:
makeprg=make
:make 的默认命令是外部的 make 命令。若想修改 :make 命令,使每次运行它时执行 g++ <your-file-name>,请运行:
:set makeprg=g++\ %
\ 用于转义 g++ 后的空格。Vim 中 % 符号代表当前文件。因此,g++\ % 命令等于运行 g++ hello.cpp。
转到 ./hello.cpp 然后运行 :make,Vim 将编译 hello.cpp 并输出 a.out(因为您没有指定输出)。让我们重构一下,使用去掉扩展名的原始文件名来命名编译后的输出。运行下面的命令(或将它们添加到vimrc):
:set makeprg=g++\ %\ -o\ %<
上面的命令分解如下:
g++\\ %如上所述,等同于运行g++ <your-file>。-o输出选项。%<在 Vim 中代表了没有扩展名的当前文件名(如hello.cpp变成hello)。
当您在 ./hello.cpp 中运行 :make 时,它将编译为 ./hello。要在 ./hello.cpp 中快速地执行 ./hello,可以运行 :!./%<。同样,它等同于运行 :!./<无后缀的当前文件名>。
查阅 :h :compiler 和 :h write-compiler-plugin 可以了解更多信息。
保存时自动编译
有了自动化编译,您可以让生活更加轻松。回想一下,您可以使用 Vim 的 autocmd 来根据某些事件自动执行操作。例如,要自动在每次保存后编译 .cpp 文件,您可以将下面内容添加到vimrc:
:autocmd BufWritePost *.cpp make
现在您每次保存 .cpp 文件后,Vim 都将自动执行 make 命令。
切换编译器
Vim 有一个 :compiler 命令可以快速切换编译器。您的 Vim 可能附带了一些预构建的编译配置。要检查您拥有哪些编译器,请运行:
:e $VIMRUNTIME/compilers/<tab>
您应该会看到一个不同编程语言的编译器列表。
若要使用 :compiler 命令,假设您有一个 ruby 文件 hello.rb,内容是:
puts "Hello ruby"
回想一下,如果运行 :make,Vim 将执行赋值给 makeprg 的任何命令(默认是 make)。如果您运行:
:compiler ruby
Vim 执行 $VIMRUNTIME/compiler/ruby.vim 脚本,并将 makeprg 更改为使用 ruby 命令。现在如果您运行 :set makeprg?,它会显示 makeprg=ruby(这取决于您 $VIMRUNTIME/compiler/ruby.vim 里的内容,如果您有其他自定义的 ruby 编译器,您的结果可能会有不同)。:compiler <your-lang> 命令允许您快速切换至其他编译器。如果您的项目使用多种语言,这会非常有用。
您不必使用 :compiler 或 makeprg 来编译程序。您可以运行测试脚本、分析文件、发送信号或任何您想要的内容。
创建自定义编译器
让我们来创建一个简单的 Typescript 编译器。先在您的设备上安装 Typescript(npm install -g typescript),安装完后您将有 tsc 命令。如果您之前没有尝试过 typescript,tsc 将 Typescript 文件编译成 Javascript 文件。假设您有一个 hello.ts 文件:
const hello = "hello";
console.log(hello);
运行 tsc hello.ts 后,它将被编译成 hello.js。然而,如果您的 hello.ts 文件中有如下内容:
const hello = "hello";
hello = "hello again";
console.log(hello);
这会抛出错误,因为不能更改一个 const 变量。运行 tsc hello.ts 的错误如下:
hello.ts:2:1 - error TS2588: Cannot assign to 'person' because it is a constant.
2 person = "hello again";
~~~~~~
Found 1 error.
要创建一个简单的 Typescript 编译器,请在您的 ~/.vim/ 目录中新添加一个 compiler 目录(即 ~/.vim/compiler/),接着创建 typescript.vim 文件(即 ~/.vim/compiler/typescript.vim),并添加如下内容:
CompilerSet makeprg=tsc
CompilerSet errorformat=%f:\ %m
第一行将 makeprg 设置为运行 tsc 命令。第二行将错误格式设置为显示文件(%f),后跟冒号(:)和转义的空格(\ ),最后是错误消息(%m)。查阅 :h errorformat 可了解更多关于错误格式的信息。
您还可以阅读一些预制的编译器,看看它们是如何实现的。输入 :e $VIMRUNTIME/compiler/<some-language>.vim 查看。
有些插件可能会干扰 Typescript 文件,可以使用 --noplugin 标志以零插件的形式打开hello.ts 文件:
vim --noplugin hello.ts
检查 makeprg:
:set makeprg?
它应该会显示默认的 make 程序。要使用新的 Typescript 编译器,请运行:
:compiler typescript
当您运行 :set makeprg? 时,它应该会显示 tsc 了。我们来测试一下:
:make %
回想一下,% 代表当前文件。看看您的 Typescript 编译器是否如预期一样工作。运行 :copen 可以查看错误列表。
异步编译器
有时编译可能需要很长时间。在等待编译时,您不会想眼睁睁盯着已冻结的 Vim 的。如果可以异步编译,就可以在编译期间继续使用 Vim 了,岂不美哉?
幸运的是,有插件来运行异步进程。有两个比较好的是:
在这一章中,我将介绍 vim-dispatch,但我强烈建议您尝试上述列表中所有插件。
Vim 和 NeoVim 实际上都支持异步作业,但它们超出了本章的范围。如果您好奇,可以查阅 :h job-channel-overview.txt。
插件:Vim-dispatch
Vim-dispatch 有几个命令,最主要的两个是 :Make 和 :Dispatch。
异步Make
Vim-dispatch 的 :Make 命令与 Vim 的 :make 相似,但它以异步方式运行。如果您正处于 Javascript 项目中,并且需要运行 npm t,可以将 makeprg 设置为:
:set makeprg=npm\\ t
如果运行:
:make
Vim 将执行 npm t。但同时,您只能盯着冻结了的屏幕。有了 vim-dispatch,您只需要运行:
:Make
Vim 将启用后台进程异步运行 npm t,同时您还能在 Vim 中继续编辑您的文本。棒极了!
异步调度(Dispatch)
:Dispatch 命令的工作方式和 :compiler 及 :! 类似,它可以在Vim中运行任意外部命令。
假设您在 ruby spec 文件中,需要执行测试,可以运行:
:Dispatch rspec %
Vim 将对当前文件异步运行 rspec 命令。
自动调度
Vim-dispatch 有一个缓冲区变量b:dispatch,您可以配置它来自动执行特定命令,您可以利用 autocmd和它一起工作。如果在您的 vimrc 中添加如下内容:
autocmd BufEnter *_spec.rb let b:dispatch = 'bundle exec rspec %'
现在每当您进入(BufEnter)一个以 _spec.rb 结尾的文件,运行:Dispatch 将自动执行 bundle exec rspec <your-current-ruby-spec-file>。
聪明地学习编译
在本章中,您了解到可以使用 make 和 compiler 命令从Vim内部异步运行 任何 进程,以完善您的编程工作流程。Vim 拥有通过其他程序来扩展自身的能力,这使其变得强大。
第20章 视图、会话和 Viminfo
当您做了一段时间的项目后,您可能会发现这个项目逐渐形了成自己的设置、折叠、缓冲区、布局等,就像住了一段时间公寓后,精心装饰了它一样。问题是,关闭 Vim 后,所有的这些更改都会丢失。如果能保留这些更改,等到下次打开 Vim 时,一切恢复如初,岂不美哉?
本章中,您将学习如何使用 视图、会话 和 Viminfo 来保存项目的“快照”。
视图
视图是这三个部分(视图、会话、Viminfo)中的最小子集,它是单个窗口相关设置的集合。如果您长时间在一个窗口上工作,并且想要保留其映射和折叠,您可以使用视图。
我们来创建一个 foo.txt 文件:
foo1
foo2
foo3
foo4
foo5
foo6
foo7
foo8
foo9
foo10
在这个文件中,做三次修改:
- 在第 1 行,创建一个手动折叠
zf4j(折叠接下来 4 行)。 - 更改
number设置:setlocal nonumber norelativenumber。这会移除窗口左侧的数字指示器。 - 创建本地映射,每当按一次
j时,向下两行::nnoremap <buffer> j jj。
您的文件看起来应该像:
+-- 5 lines: foo1 -----
foo6
foo7
foo8
foo9
foo10
配置视图属性
运行:
:set viewoptions?
默认情况下会显示(根据您的 vimrc 可能会有所不同):
viewoptions=folds,cursor,curdir
我们来配置 viewoptions。要保留的三个属性分别是折叠、映射和本地设置选项。如果您的设置和我的相似,那么您已经有了 folds 选项。运行下列命令使视图记住 localoptions:
:set viewoptions+=localoptions
查阅 :h viewoptions 可了解 viewoptions 的其他可用选项。现在运行 :set viewoptions?,您将看到:
viewoptions=folds,cursor,curdir,localoptions
保存视图
在 foo.txt 窗口经过适当折叠并设置了 nonumber norelativenumber 选项后,现在我们来保存视图。运行:
:mkview
Vim 创建了一个视图文件。
视图文件
您可能会想“Vim 将这个视图文件保存到哪儿了呢?”,运行下列命令就可以看到答案了:
:set viewdir?
默认情况下会显示 ~/.vim/view(根据您的操作系统,可能会有不同的路径。查阅 :h viewdir 获得更多信息)。如果您运行的是基于Unix的操作系统,想修改该路径,可以在您的 vimrc 中添加下列内容:
set viewdir=$HOME/else/where
加载视图文件
关闭并重新打开 foo.txt,您会看到原来的文本,没有任何改变。这是预期行为。运行下列命令可以加载视图文件:
:loadview
现在您将看到:
+-- 5 lines: foo1 -----
foo6
foo7
foo8
foo9
foo10
那些折叠、本地设置以及映射都恢复了。如果您细心还可以发现,光标位于上一次您运行 :mkview 时所处的行上。只要您有 cursor 选项,视图将记住光标位置。
多个视图
Vim 允许您保存 9 个编号的视图(1-9)。
假设您想用 :9,10 fold 来额外折叠最后两行,我们把这存为视图 1。运行:
:mkview 1
如果您又想用 :6,7 fold 再折叠一次,并存为不同的视图,运行:
:mkview 2
关闭并重新打开 foo.txt 文件,运行下列命令可以加载视图 1:
:loadview 1
要加载视图 2,运行:
:loadview 2
要加载原始视图,运行:
:loadview
自动创建视图
有一件可能会发生的很倒霉的事情是,您花了很长时间在一个大文件中进行折叠,一不小心关闭了窗口,接着丢失了所有折叠信息。您可以在 vimrc 中添加下列内容,使得在关闭缓冲区后 Vim 能自动创建视图,防止此类灾难发生:
autocmd BufWinLeave *.txt mkview
另外也能在打开缓冲区后自动加载视图:
autocmd BufWinEnter *.txt silent loadview
现在,当您编辑 txt 文件时,不用再担心创建和加载视图了。但也注意,随着时间的推移,视图文件会不断积累,记得每隔几个月清理一次。
会话
如果说视图保存了某个窗口的设置,那么会话则保存了所有窗口(包括布局)的信息。
创建新会话
假设您在 foobarbaz 工程中编辑着 3 个文件:
foo.txt 的内容:
foo1
foo2
foo3
foo4
foo5
foo6
foo7
foo8
foo9
foo10
bar.txt 的内容:
bar1
bar2
bar3
bar4
bar5
bar6
bar7
bar8
bar9
bar10
baz.txt 的内容:
baz1
baz2
baz3
baz4
baz5
baz6
baz7
baz8
baz9
baz10
假设您的窗口布局如下所示(适当地使用 split 和 vsplit 来放置):
要保留这个外观,您需要保存会话。运行:
:mksession
与默认存储在 ~/.vim/view 的 mkview 不同,mksession 在当前目录存储会话文件(Session.vim)。如果好奇,您可以看看文件。
如果您想将会话文件另存他处,可以将参数传递给 mksession:
:mksession ~/some/where/else.vim
使用 ! 来调用命令可以覆盖一个已存在的会话文件(:mksession! ~/some/where/else.vim)。
加载会话
运行下列命令可以加载会话:
:source Session.vim
现在 Vim 看起来就像您离开它时的样子!或者,您也可以从终端加载会话文件:
vim -S Session.vim
配置会话属性
您可以配置会话要保存的属性。若要查看当前哪些属性正被保存,请运行:
:set sessionoptions?
我的显示:
blank,buffers,curdir,folds,help,tabpages,winsize,terminal
如果在保存会话时不想存储 terminal,可以运行下列命令将其从会话选项中删除:
:set sessionoptions-=terminal
如果要在保存会话时存储 options,请运行:
:set sessionoptions+=options
下面是一些 sessionoptions 可以存储的属性:
blank存储空窗口buffers存储缓冲区folds存储折叠globals存储全局变量(必须以大写字母开头,并且至少包含一个小写字母)options存储选项和映射resize存储窗口行列winpos存储窗口位置winsize存储窗口大小tabpages存储选项卡unix以 Unix 格式存储文件
查阅 :h 'sessionoptions' 来获取完整列表。
会话是保存项目外部属性的好工具。但是,一些内部属性不存储在会话中,如本地标记、寄存器、历史记录等。要保存它们,您需要使用 Viminfo!
Viminfo
如果您留意,在复制一个单词进寄存器 a,再退出并重新打开 Vim 后,您仍然可以看到存储在寄存器中的文本。这就是 Viminfo 的功劳。没有它,在您关闭 Vim 后,Vim 会忘记这些寄存器。
如果您使用 Vim 8 或更高版本,Vim 会默认启用 Viminfo。因此您可能一直在使用 Viminfo,而您对它毫不知情!
您可能会问:Viminfo 存储了什么?与会话有何不同?
要使用 Viminfo,您必须启用了 +viminfo 特性(:version)。Viminfo 存储着:
- 命令行历史记录。
- 字符串搜索历史记录。
- 输入行历史记录。
- 非空寄存器的内容。
- 多个文件的标记。
- 文件标记,它指向文件中的位置。
- 上次搜索 / 替换模式(用于 “n” 和 “&”)。
- 缓冲区列表。
- 全局变量。
通常,会话存储“外部”属性,Viminfo 存储“内部”属性。
每个项目可以有一个会话文件,而 Viminfo 与会话不同,通常每台计算机只使用一个 Viminfo。Viminfo 是项目无关的。
对于 Unix,Viminfo 的默认位置是 $HOME/.viminfo(~/.viminfo)。如果您用其他操作系统,Viminfo 位置可能会有所不同。可以查阅 :h viminfo-file-name。每一次您做出的“内部”更改,如将文本复制进一个寄存器,Vim 都会自动更新 Viminfo 文件。
请确保您设置了 nocompatible 选项(set nocompatible),否则您的 Viminfo 将不起作用。
读写 Viminfo
尽管只使用一个 Viminfo 文件,但您还是可以创建多个 Viminfo 文件。使用 :wviminfo 命令(缩写为 :wv)来创建多个 Viminfo 文件。
:wv ~/.viminfo_extra
要覆盖现有的 Viminfo 文件,向 wv 命令多添加一个叹号:
:wv! ~/.viminfo_extra
Vim 默认情况下会读取 ~/.viminfo 文件。运行 :rviminfo(缩写为 :rv)可以读取不同的 Vimfile 文件:
:rv ~/.viminfo_extra
要在终端使用不同的 Viminfo 文件来启动 Vim,请使用 “i” 标志:
vim -i viminfo_extra
如果您要将 Vim 用于不同的任务,比如写代码和写作,您可以创建两个 Viminfo,一个针对写作优化,另一个为写代码优化。
vim -i viminfo_writing
vim -i viminfo_coding
不使用 Viminfo 启动 Vim
要不使用 Viminfo 启动 Vim,可以在终端运行:
vim -i NONE
要永不使用 Viminfo,可以在您的 vimrc 文件添加:
set viminfo="NONE"
配置 Viminfo 属性
和 viewoptions 以及 sessionoptions 类似,您可以用 viminfo 选项指定要存储的属性。请运行:
:set viminfo?
您会得到:
!,'100,<50,s10,h
看起来有点晦涩难懂。命令分解如下:
!保存以大写字母开头、却不包含小写字母的全局变量。回想一下g:代表了一个全局变量。例如,假设您写了赋值语句let g:FOO = "foo",Viminfo 将存储全局变量FOO。然而如果您写了let g:Foo = "foo",Viminfo 将不存储它,因为它包含了小写字母。没有!,Vim 不会存储这些全局变量。'100代表标记。在这个例子中,Viminfo 将保存最近 100 个文件的本地标记(a-z)。注意,如果存储的文件过多,Vim 会变得很慢,1000 左右就可以了。<50告诉 Viminfo 每个寄存器最多保存多少行(这个例子中是 50 行)。如果我复制 100 行文本进寄存器 a("ay99j)后关闭 Vim,下次打开 Vim 并从寄存器 a("ap)粘贴时,Vim 最多只粘贴 50 行;如果不指定最大行号, 所有 行都将被保存;如果指定 0,什么都不保存了。s10为寄存器设置大小限制(kb)。在这个例子中,任何大于 10kb 的寄存器都会被排除。h禁用高亮显示(hlsearch时)。
可以查阅 :h 'viminfo' 来了解其他更多选项。
聪明地使用视图、会话和 Viminfo
Vim 能使用视图、会话和 Viminfo 来保存不同级别的 Vim 环境快照。对于微型项目,可以使用视图;对于大型项目,可以使用会话。您应该花些时间来查阅视图、会话和 Viminfo 提供的所有选项。
为您的编辑风格创建属于您自己的视图、会话和 Viminfo。如果您要换台计算机使用 Vim,只需加载您的设置,立刻就会感到就像在家里的工作环境一样!
第21章 多文件操作
多文件编辑更新是一个值得掌握、非常有用的编辑工具。前面您已经学会了如何使用 cfdo 命令在多个文本中进行更新。本章,您将学到如何在Vim中进行多文件编辑的更多不同方法。
在多个文件中执行命令的几种方法
要在多个文件中执行命令,Vim有8种方法:
- 参数列表 (
argdo) - 缓冲区列表 (
bufdo) - 窗口列表 (
windo) - tab 列表(
tabdo) - 快速修复列表 (
cdo) - 文件方式的快速修复列表 (
cfdo) - 位置列表 (
ldo) - 文件方式的位置列表 (
lfdo)
实际上,大部分时间您可能只会用到1种或2种(就我个人而言,我使用 cdo 和 argdo比其他的多得多),但了解所有可行方法还是很有用的,这样您就可以选择一个最符合您个人编辑风格的方法。
学习所有8个命令可能听起来让人有点打退堂鼓。但实际上,这些命令工作方式很相似。学习了其中一个后,再学习剩余的将容易的多。它们的运行方式都大体相同:分别创建一个列表(列表中的元素根据命令有所不同),然后向列表传递一个您想执行的命令。
参数列表
参数列表是最基础的列表。它创建一个文件列表。要想为 file1, file2, file3创建文件列表,您可以执行:
:args file1 file2 file3
您也可以传递一个通配符(*),所以如果您想为当前目录下所有的 .js 文件创建一个列表,运行:
:args *.js
如果您想为当前目录下所有以 “a” 开头的Javascript文件创建列表,运行:
:args a*.js
(*)通配符匹配当前目录下的1个或多个任意文件名中的字符。但如果您想在某个目录下进行递归搜索怎么办呢?您可以使用双通配符(**)。要得到您当前位置下所有子目录中的Javascript文件,运行:
:args **/*.js
您运行了 args 命令后,您的当前buffer将会切换到列表中的第一个文件。运行 :args可以查看您刚才创建的文件列表。当您创建好了您的列表后,您就可以遍历它们了。:first 将让您跳至列表中的第一个文件。:last 将跳到最后一个文件。运行:next可以在列表中一次向前移动一个文件。运行 :prev可以在列表中一次向后移动一个文件。运行:wnext 和 :wprev命令,在向前/向后移动文件的同时还会保存修改。查阅 : arglist 了解更多导航命令。
参数列表在定位某个特定类型的文件或少量文件时特别有用。假如您需要将所有 yml 文件中的donut 更新为 pancake。运行:
:args **/*.yml
:argdo %s/donut/pancake/g | update
注意如果您再次执行 args 命令,它将覆盖先前的列表。比如,如果您先前运行了:
:args file1 file2 file3
假设这些文件都是存在的,那么现在您的列表为 file1, file2,以及 file3。然后再运行:
:args file4 file5
您的初始列表 file1, file2, file3将被覆盖为 file4, file5。如果您的参数列表中已经有了 file1, file2, file3 ,而您想将 file4, file5 添加到初始列表中,请使用 :arga命令。运行
:arga file4 file5
现在您的列表为file1, file2, file3, file4, file5。
如果您运行 :arga 时没有给任何参数,Vim会添加当前buffer到参数列表中。例如,如果您的参数列表中已经有了 file1, file2, file3,而您当前buffer是 file5,运行 :arga 将添加 file5 到您的列表中。
在前面的命令(:argdo %s/donut/pancake/g)中您已经看到过了,当您创建好列表后就可以向它传递任意命令行命令。其他的一些示例:
- 删除参数列表所有文件内包含 “dessert” 的行, 运行
:argdo g/dessert/d. - 在参数列表每个文件中执行宏a(假设您已经在a中录好了一个宏),运行
:argdo norm @a. - 向参数列表所有文件的第一行插入”hello “+文件名 ,运行
:argdo 0put='hello ' . @%(译者注:在英文版中,原作者给出的命令是:argdo 0put='hello ' .. @:,貌似这个命令有问题)。
把所有工作完成后,别忘了使用 :update 命令保存(:update只会保存当前buffer,要保存列表所有文件的修改,请用 :argdo update)。
有时候您仅仅需要在参数列表的前n个文件执行某条命令。如果是这种情况,只需要向 argdo 命令传递一个地址就可以了。比如,要在列表的前3个文件执行替换命令,运行::1,3argdo %s/donut/pancake/g。
缓冲区列表
因为每次您创建新文件或打开文件时,Vim将它保存在一个buffer中(除非您显式地删除它),所以当您编辑新文件时,缓冲区列表就有组织地被创建了。如果您已经打开了3个文件:file1.rb file2.rb file3.rb,您的缓冲区列表就已经有了3个元素。运行 :buffers(或者:ls、或:files)可以显示缓冲区列表。要想向前或向后遍历缓冲区列表,可以使用 :bnext :bprev。要想跳至列表中第一个或最后一个buffer,可使用 :bfirst 和 :blast。
另外,这里有一个和本章内容不相关,但是很酷的缓冲区技巧:如果您的缓冲区有大量的文件,您可以使用 :ball 显示所有缓冲区。:ball 命令默认使用水平分割窗口进行显示,如果想使用垂直分割的窗口显示,运行::vertical ball
回到本章主题。在缓冲区列表中执行某个操作的方法与参数列表操作非常相似。当您创建好缓冲区列表后,您只需要在您想执行的命令前用 :bufdo 代替 :argdo就可以了。例如,如果您想将缓冲区列表内每个文件中所有的 “donut” 替换为 “pancake”并保存修改,可以运行::bufdo %s/donut/pancake/g | update。
窗口列表和选项卡(Tab)列表
窗口列表、选项卡列表的操作和参数列表、缓冲区列表同样非常相似。唯一的区别在于它们的内容和语法。
窗口操作作用在每一个打开的窗口上,使用的命令是 :windo。选项卡(Tab)操作作用在每一个打开的选项卡上,使用的命令是 :tabdo。可以查询 :h list-repeat, :h :windo和:h :tabdo,了解更多信息。
比如,如果您打开了4个窗口(您可以使用 Ctrl-w v打开一个垂直分割的窗口,也可以使用 Ctrl-w s打开一个水平分割的窗口),然后您运行 :windo 0put = 'hello' . @%,Vim将在所有打开的窗口的第一行输出 “hello”+文件名。
快速修复列表
在前面的章节中(第3章和第19章),我曾提到过快速修复(quickfix)。快速修复有很多作用,很多流行的插件都在使用快速修复提供的功能,因此值得花时间去理解它。
如果您是Vim新手,快速修复对于您可能是个新概念。回想以前您执行代码编译的时候,编译期间您可能遇到过错误,而这些错误都显示在一个特殊的窗口。这就是快速修复(quickfix)的由来。当您编译您的代码的时候,Vim会在快速修复窗口显示错误信息,您可以稍后去解决。许多现代语言已经不再需要进行显式地编译,但快速修复并没有被淘汰。现在,人们使用快速修复来做各种各样的事,比如显示虚拟终端的输入、存储搜索结果等。我们重点研究后者,存储搜索结果。
除编译命令外,某些特定的Vim命令也依赖快速修复接口。其中一种就是搜索命令,其使用过程中大量的使用了快速修复窗口,:vimgrep 和 :grep 都默认使用快速修复。
比如,如果您需要在所有的Javascript文件中递归地搜索 “donut”,您可以运行:
:vimgrep /donut/ **/*.js
“donut”的搜索结果存储在快速修复窗口中。要查看快速修复窗口的结果,运行:
:copen
要关闭快速修复窗口,运行:
:cclose
在快速修复列表中向前或向后遍历,运行:
:cnext
:cprev
跳至第一个或最后一个匹配的元素,运行:
:cfirst
:clast
在前面我提到过,有两种快速修复命令:cdo 和 cfdo 。它们有什么区别?cdo 在修复列表中的每一个元素上执行命令,而 cfdo 在修复列表中的每一个文件上执行命令。
让我讲清楚一点,假设运行完上面的 vimgrep 命令后,您找到以下结果:
- 1 result in
file1.js - 10 results in
file2.js
如果您运行 :cfdo %s/donut/pancake/g, 这个命令将会在 file1.js 和 file2.js 上分别有效地运行一次%s/donut/pancake/g. 它执行的次数与 匹配结果中文件的数量 相同。因为搜索结果中有2个文件,因此Vim在 file1.js 上运行一次替换命令,在 file2.js 上再运行一次替换命令。 尽管在第二个文件中有10个搜索结果,但 cfdo 只关注快速修复列表中有多少个文件。
而如果您运行 :cdo %s/donut/pancake/g ,这个命令将会在 file1.js 上有效运行一次,然后在 file2.js 上运行10次。它执行的次数与 快速修复列表中元素的数量 相同。因为在 file1.js 上找到1个匹配结果,在 file2.js 上找到10个匹配结果,因此它执行的总次数是11次。
由于您要在列表中运行的命令是 %s/donut/pancake/g ,所以使用 cfdo命令是比较合理的。而使用 cdo 是不合理的,因为它将在 file2.js 中运行10次 %s/donut/pancake/g命令(%s已经是一个针对整个文件的替换操作)。一个文件运行一次 %s 就足够了。如果您使用 cdo,则传给它的命令应当改为 s/donut/pancake/g 才是合理的。
那到底什么时候该用 cfdo?什么时候该用 cdo? 这应当想一想您要传递的命令的作用域,要看命令作用域是整个文件(比如 :%s 或 :g)?还是某一行(比如 :s 或 :!)?
位置列表
位置列表在某种意义上和快速修复列表很像。Vim也使用一个特殊的窗口来显示位置列表的信息。区别在于:您任何时候都只能有1个快速修复列表,而位置列表则是,有多少个窗口就可以有多少个位置列表。
假设您打开了两个窗口,其中一个窗口显示 food.txt ,而另一个显示 drinks.txt。在 food.txt里面,运行一个位置列表搜索命令 :lvimgrep (:vimgrep命令关于位置列表的一个变体)。
:lvim /bagel/ **/*.md
Vim将为 food.txt所在 窗口创建一个位置列表,用于存储所有的bagel搜索结果。用 :lopen命令可以查看位置列表。现在转到另一个窗口 drinks.txt,运行:
:lvimgrep /milk/ **/*.md
Vim将为 drinks.txt所在 窗口再创建一个 单独的位置列表,用于存储所有关于milk的搜索结果。
对于每个不同的窗口中您运行的位置命令,Vim都会单独创建一个位置列表。如果您有10个不同的窗口,您就可以有最多10个不同的位置列表。对比前面介绍的快速修复列表,快速修复列表任何时候都只能有1个。就算您有10个不同的窗口,您也只能有1个快速修复列表。
大多数位置列表命令都和快速修复列表命令相似,唯一不同就是位置列表命令有一个 l-前缀,比如: :lvimgrep, :lgrep, 还有 :lmake。在快速修复列表命令中与之对应的是: :vimgrep, :grep, 以及 :make。操作位置列表窗口的方式和快速修复窗口也很相似::lopen, :lclose, :lfirst, :llast, :lnext, 还有:lprev,与之对应快速修复版本是::copen, :cclose, :cfirst, :clast, :cnext, and :cprev。
两个位置列表参数的多文件操作命令也和快速修复列表的多文件操作命令也很类似::ldo 和 :lfdo。:ldo 对位置列表中每一个元素执行命令,而 :lfdo 对位置列表中每一个文件执行命令。可以查阅 :h location-list了解更多信息。
在Vim中运行多文件操作命令
在编辑工作中,知道如何进行多文件操作是一个非常有用的技能。当您需要在多个文件中改变一个变量名字的时候,您肯定想一个操作就全部搞定。Vim有8种不同的方法支持你完成这个事。
事实上,您可能并不会用到所有8种方法。您会慢慢倾向于其中1中或2种。当您刚开始时,选择其中1个(我个人建议从参数列表开始 :argdo)并掌握它。当您习惯了其中1个,然后再学下一个。您将会发现,学习第二个、第三个、第四个时要容易多了。记得要创造性的使用,即将它和其他各种不同命令组合起来使用。坚持练习直到您可以不经思考地高效的使用它。让它成为您的肌肉记忆。
就像前面已经说过的,您现在已经掌握了Vim的编辑功能。恭喜您!
第22章 Vimrc
在先前的章节中,您学习了如何使用Vim。在本章,您将学习如何组织和配置Vimrc。
Vim如何找到Vimrc
对于Vimrc,常见的理解是在根目录下添加一个 .vimrc 点文件(根据您使用的操作系统,文件路径名可能不同)。
实际上,Vim在多个地方查找vimrc文件。下面是Vim检查的路径:
$VIMINIT$HOME/.vimrc$HOME/.vim/vimrc$EXINIT$HOME/.exrc$VIMRUNTIME/default.vim
当您启动Vim时,它将在上面列出的6个位置按顺序检查vimrc文件,第一个被找到的vimrc文件将被加载,而其余的将被忽略。
首先,Vim将查找环境变量 $VIMINIT。如果没有找到,Vim将检查 $HOME/.vimrc。如果还没找到,VIm就检查 $HOME/.vim/vimrc。如果Vim找到了vimrc文件,它就停止查找,并使用 $HOME/.vim/vimrc。
关于第一个位置,$VIMINIT 是一个环境变量。默认情况下它是未定义的。如果您想将 ~/dotfiles/testvimrc 作为 $VIMINTI 的值,您可以创建一个包含那个vimrc路径的环境变量。当您运行 export VIMINIT='let $MYVIMRC="$HOME/dotfiles/testvimrc" | source $MYVIMRC'后,VIm将使用 ~/dotfiles/testvimrc 作为您的vimrc文件。
第二个位置,$HOME/.vimrc 是很多Vim用户习惯使用的路径。$HOME 大部分情况下是您的根目录(~)。如果您有一个 ~/.vimrc 文件,Vim将使用它作为您的vimrc文件。
第三个,$HOME/.vim/vimrc,位于 ~/.vim 目录中。您可能已经有了一个 ~/.vim 目录用于存放插件、自定义脚本、或视图文件。注意这里的vimrc文件名没有“点”($HOME/.vim/.vimrc 不会被识别,但 $HOME/.vim/vimrc能被识别)。
第四个,$EXINIT 工作方式与 $VIMINIT 类似。
第五个,$HOME/.exrc 工作方式与 $HOME/.vimrc 类似。
第六个,$VIMRUNTIME/defaults.vim 是Vim编译时自带的默认vimrc文件。在我的电脑中,我是使用Homebrew安装的Vim8.2,所以我的路径是(/usr/local/share/vim/vim82)。如果Vim在前5个位置都没有找到vimrc文件,它将使用这个Vim自带的vimrc文件。
在本章剩余部分,我将假设vimrc使用的路径是 ~/.vimrc。
应该把什么放在Vimrc中?
我刚开始配置Vimrc时,曾问过一个问题,“我究竟该把什么放在Vimrc文件中?”。
答案是,“任何您想放的东西”。 直接复制粘贴别人的vimrc文件的确是一个诱惑,但您应当抵制这个诱惑。如果您仍然坚持使用别人的vimrc文件,确保您知道这个vimrc干了什么,为什么他/她要用这些设置?以及他/她如何使用这些设置?还有最重要的是,这个vimrc文件是否符合你的实际需要?别人使用并不代表您也要使用。
Vimrc基础内容
简单地说,一个vimrc是以下内容的集合:
- 插件
- 设置
- 自定义函数
- 自定义命令
- 键盘映射
当然还有一些上面没有提到的内容,但总体说,已经涵盖了绝大部分使用场景。
插件
在前面的章节中,我曾提到很多不同的插件,比如fzf.vim, vim-mundo, 还有 vim-fugitive.
十年前,管理插件插件是一个噩梦。但随着很多现代插件管理器的开发,现在安装插件可以在几秒内完成。我现在正在使用vim-plug作为我的插件管理器,所以我在本节中将使用它。相关概念和其他流行的插件管理器应该是类似的。我强烈建议您多试试几个插件管理器,比如:
除了上面列出的,还有很多插件管理器,可以随便看看。要想安装 vim-plug,如果您使用的是Unix,运行:
curl -fLo ~/.vim/autoload/plug.vim --create-dirs https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
要添加新的插件,将您的插件名(比如,Plug 'github-username/repository-name') 放置在 call plug#begin() 和 call plug#end() 之间的行中. 所以,如果您想安装 emmet-vim 和 nerdtree,将下面的片段放到您的vimrc中:
call plug#begin('~/.vim/plugged')
Plug 'mattn/emmet-vim'
Plug 'preservim/nerdtree'
call plug#end()
然后保存修改,加载当前vimrc (:source %), 然后运行 :PlugInstall 安装插件。
如果以后您想删除不使用的插件,您只需将插件名从 call 代码块之间移除,保存并加载,然后运行 :PlugClean 命令将它从机器上删除。
Vim 8 有自己的内置包管理器。您可以查阅 :h packages 了解更多信息。在后面一章中,我将向您展示如何使用它。
设置
在任意一个vimrc文件中都可以看到大量的 set 选项。 如果您在命令行模式中运行 set 命令,它只是暂时的。当您关闭Vim,设置就会丢失。比如,为了避免您每次运行Vim时都必须在命令行模式运行 :set relativenumber number 命令,您可以将这个命令添加在vimrc中:
set relativenumber number
有一些设置需要您赋予一个值,比如 set tabstop=2。想了解一个设置可以接收什么类型的值,可以查看帮助页。
您也可以使用 let 来代替 set(确保在选项前添加一个 &号)。使用 let ,您可以使用表达式进行赋值。比如,要想仅当某个路径存在时,才将该路径赋予 'dictionary' 选项:
let s:english_dict = "/usr/share/dict/words"
if filereadable(s:english_dict)
let &dictionary=s:english_dict
endif
在后面的章节中您将了解关于Vimscript赋值和条件的知识。
要查看Vim中所有可用的选项,查阅 :h E355。
自定义函数
Vimrc是一个很好的用来放置自定义函数的地方。在后面的章节中您将学习如何写您自己的Vimscript函数。
自定义命令
您可以使用 command 创建一个自定义命令行命令。
比如,创建一个用于显示今天日期的基本命令 GimmeDate:
:command! GimmeDate echo call("strftime", ["%F"])
当您运行 :GimmeDate 时,Vim将显示一个类似 “2021-01-1”的日期。
要创建一个可以接收输入的基本命令,您可以使用 <args> 。如果您想向 GimmeDate 传递一个时间/日期格式参数:
:command! GimmeDate echo call("strftime", [<args>])
:GimmeDate "%F"
" 2020-01-01
:GimmeDate "%H:%M"
" 11:30
如果您想限定参数的数目,您可以使用 -nargs 标志。-nargs=0 表示没有参数,-nargs=1 表示传递1个参数,-nargs=+ 表示至少1个参数,-nargs=* 表示传递任意数量的参数,-nargs=? 表示传递0个或1个参数。如果您想传递n个参数,使用 -nargs=n(这里 n 是一个任意整数)。
<args> 有两个变体:<f-args> 和 <q-args> 。前者用来向Vimscript函数传递参数,后者用来将用户输入自动转换为字符串。
使用 args:
:command! -nargs=1 Hello echo "Hello " . <args>
:Hello "Iggy"
" returns 'Hello Iggy'
:Hello Iggy
" Undefined variable error
使用 q-args:
:command! -nargs=1 Hello echo "Hello " . <q-args>
:Hello Iggy
" returns 'Hello Iggy'
使用 f-args:
:function! PrintHello(person1, person2)
: echo "Hello " . a:person1 . " and " . a:person2
:endfunction
:command! -nargs=* Hello call PrintHello(<f-args>)
:Hello Iggy1 Iggy2
" returns "Hello Iggy1 and Iggy2"
当您学了关于Vimscript函数的章节后,上面的函数将更有意义。
查阅 :h command 和 :args 了解更多关于command和args的信息。
键盘映射
如果您发现您重复地执行一些相同的复杂操作,那么为这些复杂操作建立一个键盘映射将会很有用:
比如,在我的vimrc文件中有2个键盘映射:
nnoremap <silent> <C-f> :GFiles<CR>
nnoremap <Leader>tn :call ToggleNumber()<CR>
在第一个中,我将 Ctrl-F 映射到 fzf.vim 插件的 :Gfiles 命令(快速搜索Git文件)上。在第二个中,我将 <leader>tn 映射到调用一个自定义函数 ToggleNumber (切换 norelativenumber 和 relativenumber 选项)。Ctrl-f 映射覆盖了Vim的原生的页面滚动。如果发生冲突,您的映射将会覆盖Vim的设置。因为从几乎从来不用Vim原生的页面滚动功能,所以我认为可以安全地覆盖它。
另外,在 <Leader>tn 中的 “leader” 键到底是什么?
Vim有一个leader键用来辅助键盘映射。比如,我将 <leader>tn 映射为运行 ToggleNumber() 函数。如果没有leader键,我可能会用 tn,但Vim中的 t 已经用做其他功能(”till”搜索导航命令)了。有了leader键,我现在先按定义好的leader键作为开头,然后按 tn,而不用干扰已经存在的命令。您可以设置leader键作为您映射的连续按键的第一个按键。默认Vim使用反斜杠作为leader键(所以 <Leader>tn 会变成 “反斜杠-t-n”)。
我个人喜欢使用空格 <Space> 作为leader键,代替默认的反斜杠。要想改变您的leader键,将下面的文本添加到您的vimrc中:
let mapleader = "\<space>"
上面的 nnoremap 命令可以分解为三个部分:
n表示普通模式。nore表示禁止递归。map是键盘映射命令。
如果不想使用 nnoremap,您至少也得使用 nmap (nmap <silent> <C-f> :Gfiles<CR>)。但是,最好还是使用禁止递归的版本,这样是为了避免键盘映射时潜在的无限循环风险。
如果您进行键盘映射时不使用禁止递归,下面例子演示了会发生什么。假设您想给 B 添加一个键盘映射,用来在一行的末尾添加一个分号,然后跳回前一个词组(回想一下,B 是Vim普通模式的一个导航命令,用来跳回前一个词组)。
nmap B A;<esc>B
当您按下 B …哦豁,Vim开始失控了,开始无止尽的添加;(用 Ctrl-c终止)。为什么会发生这样的情况?因为在键盘映射 A;<esc>B中,这个 B不再是Vim原生的导航命令,它已经被映射到您刚才创建的键盘映射中了。这是您实际上执行的操作序列:
A;<esc>A;<esc>A;<esc>A;esc>...
要解决这个问题,您需要指定键盘映射禁止递归:
nnoremap B A;<esc>B
现在再按一下 B 试试。这一次它成功地在行尾添加了一个 ;,然后跳回到前一个词组。这个映射中的 B 就表示Vim原生的 B了。
Vim针对不同的模式有不同的键盘映射命令。如果您想创建一个插入模式下的键盘映射 jk,用来退出插入模式:
inoremap jk <esc>
其他模式的键盘映射命令有:map(普通、可视、选择、以及操作符等待模式), vmap(可视、选择), smap(选择), xmap(可视), omap(操作符等待模式), map!(插入、命令行), lmap(插入,命令行,Lang-arg模式), cmap(命令行), 还有tmap(终端任务)。在这里我不会详细的讲解它们,要了解更多信息,查阅 :h map.txt。
创建最直观、最一致、最易于记忆的键盘映射。
组织管理Vimrc
一段时候键,您的vimrc文件就会变大且复杂得难以阅读。有两种方法让您的vimrc文件保持整洁:
- 将您的vimrc文件划分为几个文件
- 折叠您的vimrc文件
划分您的vimrc
您可以使用Vim的 :source 命令将您的vimrc文件划分为多个文件。这个命令可以根据给定的文件参数,读取文件中的命令行命令。
让我们在 ~/.vim 下创建一个子文件夹,取名为 /settings(~/.vim/settings)。名字可以取为任意您喜欢的名字。
然后你在这个文件夹下创建4个文件:
- 第三方插件 (
~/.vim/settings/plugins.vim). - 通用设置 (
~/.vim/settings/configs.vim). - 自定义函数 (
~/.vim/settings/functions.vim). - 键盘映射 (
~/.vim/settings/mappings.vim) .
在 ~/.vimrc 里面添加:
source $HOME/.vim/settings/plugins.vim
source $HOME/.vim/settings/configs.vim
source $HOME/.vim/settings/functions.vim
source $HOME/.vim/settings/mappings.vim
在 ~/.vim/settings/plugins.vim 里面:
call plug#begin('~/.vim/plugged')
Plug 'mattn/emmet-vim'
Plug 'preservim/nerdtree'
call plug#end()
在 ~/.vim/settings/configs.vim 里面:
set nocompatible
set relativenumber
set number
在 ~/.vim/settings/functions.vim 里面:
function! ToggleNumber()
if(&relativenumber == 1)
set norelativenumber
else
set relativenumber
endif
endfunc
在 ~/.vim/settings/mappings.vim 里面:
inoremap jk <esc>
nnoremap <silent> <C-f> :GFiles<CR>
nnoremap <Leader>tn :call ToggleNumber()<CR>
这样您的vimrc文件依然能够正常工作,但现在它只有4行了。
使用这样的设置,您可以轻易知道到哪去修改配置。如果您要添加一些键盘映射,就将它们添加在 /mappings.vim 文件中。以后,当您的vimrc变大时,您总是可以新建几个子文件来缩小它的大小。比如,如果您想为主题配色创建相关设置,您可以添加 ~/.vim/settings/themes.vim。
保持单独的一个Vimrc文件
如果您倾向于保持一个单独的vimrc文件,以使它更加便于携带,您可以使用标志折叠让它保持有序。在vimrc文件的顶部添加一下内容:
" setup folds }
Vim能够检测当前buffer所属的文件类型 (:set filetype?). 如果发现属于 vim 类型,您可以使用标志折叠。回想一个标志折叠的用法,它使用 } 来指明折叠的开始和结束。
添加 } 标志将您的vimrc文件其他部分折叠起来。(别忘了使用 " 对标志进行注释):
" setup folds }
" plugins }
" configs }
" functions }
" mappings }
您的vimrc文件将会看起来类似下面:
+-- 6 lines: setup folds -----
+-- 6 lines: plugins ---------
+-- 5 lines: configs ---------
+-- 9 lines: functions -------
+-- 5 lines: mappings --------
启动Vim时加载/不加载Vimrc和插件
如果您要启动Vim时,既不加载Vimrc,也不加载插件,运行:
vim -u NONE
如果您要启动Vim时,不加载Vimrc,但加载插件,运行:
vim -u NORC
如果您要启动Vim时,加载Vimrc,但不加载插件,运行
vim --noplugin
如果您要Vim启动加载一个 其他的 vimrc, 比如 ~/.vimrc-backup, 运行:
vim -u ~/.vimrc-backup
聪明地配置Vimrc
Vimrc是定制Vim时的一个重要组件,学习构建您的Vimrc最好是首先阅读他人的vimrc文件,然后逐渐地建立自己的。最好的vimrc并不是谁谁谁使用的,而是最适合您的工作需要和编辑风格的。
第23章 Vim软件包
在前面的章节中,我提到使用第三方插件管理器来安装插件。从Vim 8开始,Vim自带了一个内置的插件管理器,名叫 软件包(packages)。在本章,您将学习如何使用Vim软件包来安装插件。
要看您的Vim编译版本是否能够使用软件包,运行 :version。然后查看是否有 +packages属性。另外,您也可以运行 :echo has('packages')(如果返回1,表示可以使用软件包)。
包目录
在根目录下查看您是否有一个 ~/.vim 文件夹。如果没有就新建一个。在文件夹里面,创建一个子文件夹取名 pack(~/.vim/pack/)。Vim会在这个子文件夹内自动搜索插件。
两种加载方式
Vim软件包有两种加载机制:自动加载和手动加载。
自动加载
要想让Vim启动时自动加载插件,你需要将它们放置在 start/子目录中。路径看起来像这样:
~/.vim/pack/*/start/
现在您可能会问,为什么在pack/ 和 start/ 之间有一个 * ?这个星号可以是任意名字。让我们将它取为packdemo/:
~/.vim/pack/packdemo/start/
记住,如果您忽略这一点,用下面的路径代替的话:
~/.vim/pack/start/
软件包系统是不会正常工作的。 必须在pack/ 和 start/之间添加一个名字才能正常运行。
在这个示例中,让我们尝试安装 NERDTree 插件。用任意方法进入 start/ 目录(cd ~/.vim/pack/packdemo/start/),然后将NERDTree的仓库克隆下来:
git clone https://github.com/preservim/nerdtree.git
完成了!您已经完成了安装。下一次您启动Vim,您可以立即执行 NERDTree 命令 :NERDTreeToggle。
在 ~/.vim/pack/*/start/ 目录中,您想克隆多少插件仓库就克隆多少。Vim将会自动加载每一个插件。如果您删除了克隆的仓库(rm -rf nerdtree),那么插件就失效了。
手动加载
要想在Vim启动时手动加载插件,您得将相关插件放置在 opt/ 目录中,类似于自动加载,这个路径看起来像这样:
~/.vim/pack/*/opt/
让我们继续使用前面的 packdemo/ 这个名字:
~/.vim/pack/packdemo/opt/
这一次,让我们安装killersheep 游戏(需要Vim8.2以上版本)。进入opt/ 目录(cd ~/.vim/pack/packdemo/opt/) 然后克隆仓库:
git clone https://github.com/vim/killersheep.git
启动Vim。执行游戏的命令是 :KillKillKill。试着运行一下。Vim将会提示这不是一个有效的编辑命令。您需要首先 手动 加载插件,运行:
:packadd killersheep
现在再运行一下 :KillKillKill 。命令已经可以使用了。
您可能好奇,“为什么我需要手动加载插件?启动时自动加载岂不是更好?”
很好的问题。有时候有些插件我们并不是所有的时候都在用,比如 KillerSheep 游戏。您可能不会想要加载10个不同的游戏导致Vim启动变慢。但是偶尔当您觉得乏味的时候,您可能想要玩几个游戏,使用手动加载一些非必须的插件。
您也可以使用这个方法有条件的加载插件。可能您同时使用了Neovim和Vim,有一些插件是为NeoVim优化过的。您可以添加类似下列的内容到您的vimrc中:
if has('nvim')
packadd! neovim-only-plugin
else
packadd! generic-vim-plugin
endif
组织管理软件包
回想一下,要使用Vim的软件包系统必须有以下需求:
~/.vim/pack/*/start/
或者:
~/.vim/pack/*/opt/
实际上,*星号可以使 任意 名字,这个名字就可以用来管理您的插件。假设您想将您的插件根据类型(颜色、语法、游戏)分组:
~/.vim/pack/colors/
~/.vim/pack/syntax/
~/.vim/pack/games/
您仍然可以使用各个目录下的 start/ 和 opt/ 。
~/.vim/pack/colors/start/
~/.vim/pack/colors/opt/
~/.vim/pack/syntax/start/
~/.vim/pack/syntax/opt/
~/.vim/pack/games/start/
~/.vim/pack/games/opt/
聪明地添加插件
您可能好奇,Vim软件包是否让一些流行的插件管理器,比如 vim-pathogen, vundle.vim, dein.vim, a还有vim-plug面临淘汰?
答案永远是:“看情况而定。”
我仍然使用vim-plug,因为使用它添加、删除、更新插件很容易。如果您使用了很多插件,插件管理器的好处更加明显,因为使用它可以对很多插件进行同时更新。有些插件管理器同时也提供了一些异步功能。
如果您是极简主义者,可以尝试一下Vim软件包。如果您是一名插件重度使用者,您可能需要一个插件管理器。
第24章 Vim Rumtime
在前面的章节中,我提到Vim会自动查找一些特殊的路径,比如在~/.vim/ 中的 pack/(第23章) compiler/(第19章)。这些都是Vim runtime路径的例子。
除了上面提到的两个,Vim还有更多runtime路径。在本章,您将学习关于Vim runtime路径的高层次概述。本章的目标是向您展示它们什么时候被调用。知道这些知识能够帮您更进一步理解和定制Vim。
Runtime路径
在一台Unix机器中,其中一个vim runtime路径就是 $HOME/.vim/ (如果您用的是其他操作系统,比如Windows,您的路径可能有所不同)。要查看不同的操作系统有什么样的runtime路径,查阅 :h runtimepath。在本章,我将使用 ~/.vim/ 作为默认的runtime路径。
Plugin脚本
Vim有一个runtime路径 plugin,每次Vim启动时都会执行这个路径中的所有脚本。不要把这个名字 “plugin” 和Vim的外部插件(external plugins,比如NERDTree, fzf.vim, 等)搞混了。
进入 ~/.vim/ 目录,然后创建 plugin/ 子目录。 创建两个文件: donut.vim 和 chocolate.vim。
在 ~/.vim/plugin/donut.vim里面:
echo "donut!"
在 ~/.vim/plugin/chocolate.vim里面:
echo "chocolate!"
现在关闭Vim。下次您启动Vim,您将会看到 "donut!" 和 :chocolate! 的显示。此 plugin runtime路径可以用来执行一些初始化脚本。
文件类型检测
在开始之前,为保证检测能正常运行,确保在您的vimrc中至少包含了下列的行:
filetype plugin indent on
查阅 :h filetype-overview 了解更多信息。本质上,这条代码开启Vim的文件类型检测。
当您打开一个新的文件,Vim通常知道这个文件是什么类型。如果您有一个文件 hello.rb,运行 :set filetype? 会返回正确的相应 filetype=ruby。
Vim知道如何检测 “常见” 的文件类型(Ruby, Python, Javascript, 等)。但如果是一个自定义文件会怎样呢?您需要告诉Vim去检测它,并给它指派一个正确的文件类型。
有两种检测方法:使用文件名和使用文件内容
文件名检测
文件名检测使用一个文件的文件名来检测文件类型。当您打开 hello.rb文件时,Vim依靠扩展名 .rb 知道它是一个Ruby文件。
有两种方法实现文件名检测:一是使用 ftdetect runtime目录,二是使用 filetype.vim runtime文件。我们两个都看一看。
ftdetect/
让我们创建一个古怪(但优雅)的名字,hello.chocodonut。当您打开它后运行 :set filetype? ,因为它的后缀名不是常见的文件名,Vim不知道它是什么类型,会返回 filetype=。
您需要指示Vim将所有以 .chocodonut结尾的文件设置为 “chocodonut”类型的文件。在runtime路径根目录(~/.vim/)创建一个子目录,名为 ftdetect/ 。在子目录里面,再创建一个名叫 chocodonut.vim 的文件(~/.vim/ftdetect/chocodonut.vim),在文件里面,添加:
autocmd BufNewFile,BufRead *.chocodonut set filetype=chocodonut
当您创建新buffer或打开新buffer时,事件BufNewFile 和 BufRead 就会被触发。 *.chocodonut 意思是只有当新打开的buffer文件名后缀是 .chocodonut 时事件才会被触发。最后,set filetype=chocodonut 命令将文件类型设置为chocodonut类型。
重启Vim。新建一个 hello.chocodonut 文件然后运行 :set filetype?。它将返回 filetype=chocodonut.
好极了!只要您想,您可以将任意多的文件放置在 ftdetect/ 中。以后,如果您想扩展您的 donut 文件类型,你可以添加 ftdetect/strawberrydonut.vim, ftdetect/plaindonut.vim 等等。
在Vim中,实际上有两种方法设置文件类型。其中给一个是您刚刚使用的 set filetype=chocodonut。另一种方法是运行 setfiletype chocodonut。前一个命令 set filetype=chocodonut 将 总是 设置文件类型为chocodonut。 而后者setfiletype chocodonut只有当文件类型尚未设置时,才会将文件类型设置为chocodonut。
文件类型文件
第二种文件类型检测需要你创建一个名为 filetype.vim的文件,并将它放置在根目录(~/.vim/filetype.vim)。在文件内添加一下内容:
autocmd BufNewFile,BufRead *.plaindonut set filetype=plaindonut
创建一个名为 hello.plaindonut 的文件。当你打开它后运行 :set filetype? Vim会显示正确的自定义文件类型 filetype=plaindonut。
太好了,修改生效了。另外,如果您仔细看看 filetype.vim ,您会发现当您打开hello.plaindonut时,这个文件文件运行了多次。为防止这一点,您可以添加一个守卫,让主脚本只运行一次。更新 filetype.vim:
if exists("did_load_filetypes")
finish
endif
augroup donutfiletypedetection
autocmd! BufRead,BufNewFile *.plaindonut setfiletype plaindonut
augroup END
finish 是一个Vim命令,用来停止执行剩余的脚本。表达式"did_load_filetypes" 并 不是 一个Vim内置函数。它实际上是$VIMRUNTIME/filetype.vim 中的一个全局变量。如果您好奇,运行:e $VIMRUNTIME/filetype.vim。您将会发现以下内容:
if exists("did_load_filetypes")
finish
endif
let did_load_filetypes = 1
当Vim调用这个文件时,它会定义 did_load_filetypes 变量,并将它设置为 1 。在Vim中,1 表示真。你可以试着读完 filetype.vim 剩余的内容,看看您是否能够理解当Vim调用它时干了什么。
文件类型脚本
让我们学习如何基于文件内容检测文件类型。
假设您有一个无扩展名的文件的集合。这些文件唯一相同的地方是,第一行都是以 “donutify” 开头。您现在想给这些文件指派一个 donut 的文件类型。创建新文件,起名为 sugardonut, glazeddonut, 还有 frieddonut(没有扩展名)。在每个文件中,添加下列内容:
donutify
当您在sugardonut中运行 :set filetype?,Vim无法知道应该给这个文件指派什么文件类型,会返回 filetype=。
在runtime根目录,添加一个 scripts.vim 文件(~/.vim/scripts.vim),在文件中,添加一下内容:
if did_filetype()
finish
endif
if getline(1) =~ '^\\<donutify\\>'
setfiletype donut
endif
函数 getline(1) 返回文件第一行的内容。它检查第一行是否以 “donutify” 开头。函数 did_filetype() 是Vim的内置函数,当一个与文件类型相关的事件发生至少一次时,它返回真。它用来做守卫,防止文件类型事件反复运行。
打开文件 sugardonut 然后运行 :set filetype?,Vim现在返回 filetype=donut。如果您打开另外一个donut文件 (glazeddonut 和 frieddonut),Vim同样会将它们的文件类型定义为 donut 类型。
注意,scripts.vim 仅当Vim打开一个未知文件类型的文件时才会运行。如果Vim打开一个已知文件类型的文件,scripts.vim 将不会运行。
文件类型插件
如果您想让Vim仅当您打开一个 chocodonut 文件时才运行 chocodonut 相关的特殊脚本,而当您打开的是 plaindonut 文件时,Vim就不运行这些脚本。能否做到呢?
您可以使用文件类型插件runtime路径(~/.vim/ftplugin/)来完成这个功能。Vim会在这个目录中查找一个文件,这个文件的文件名与您打开的文件类型一样。创建一个文件,起名为chocodonut.vim (~/.vim/ftplugin/chocodonut.vim):
echo "Calling from chocodonut ftplugin"
创建另一个 ftplugin 文件,起名为plaindonut.vim (~/.vim/ftplugin/plaindonut.vim):
echo "Calling from plaindonut ftplugin"
现在,每次您打开一个 chocodonut 类型的文件时,Vim会运行 ~/.vim/ftplugin/chocodonut.vim中的脚本。每次您打开 plaindonut 类型的文件时,Vim会运行 ~/.vim/ftplugin/plaindonut.vim 中的脚本。
一个警告:每当一个buffer的文件类型被设置时(比如,set filetype=chocodonut),上述脚本就会运行一次。如果您打开3个不同的 chocodonut 文件,该脚本将运行 总共 3次。
缩进文件
Vim有一个 缩进runtime路径,其工作方式与ftplugin类似,Vim也会在这个目录中查找一个与打开的文件类型名字一样的文件。缩进runtime路径的目的是存储缩进相关的代码。如果您有文件 ~/.vim/indent/chocodonut.vim,它仅当您打开一个 chocodonut 类型的文件时执行。您可以将 chocodonut 文件中缩进相关的代码存储在这里。
颜色
Vim 有一个颜色runtime路径 (~/.vim/colors/) ,用来存储颜色主题。这个目录中的任何文件都会在命令行命令 :color 中显示出来。
如果您有一个文件 ~/.vim/colors/beautifulprettycolors.vim,当您运行 :color 然后按 Tab,您将会看到 beautifulprettycolors 出现在颜色选项中。 如果您想添加自己的颜色主题,就放在这个地方。
如果您想看其他人做的颜色主题,有一个好地方值得推荐:vimcolors。
语法高亮
Vim有一个语法runtime路径 (~/.vim/syntax/),用来定义语法高亮。
假设您有一个文件 hello.chocodonut,在文件里面有以下内容:
(donut "tasty")
(donut "savory")
虽然Vim现在知道了正确的文件类型,但所有的文本都是相同的颜色。让我们添加语法高亮规则,使 “donut” 关键词高亮显示。创建一个新的 chocodonut 语法文件 ~/.vim/syntax/chocodonut.vim,在文件中添加:
syntax keyword donutKeyword donut
highlight link donutKeyword Keyword
现在重新打开 hello.chocodonut 文件,关键词 donut 已经高亮显示了。
本章不会详细介绍语法高亮。它是一个庞大的主题。如果您感兴趣,可以查阅 :h syntax.txt。
vim-polyglot 插件非常的棒,它提供了很多流行的编程语言的语法高亮。
文档
如果您写了一个插件,您还得创建一个您自己的文档。您可以使用文档runtime路径完成这个。
让我们为 chocodonut 和 plaindonut 关键字创建一个基本文档。创建文件 donut.txt (~/.vim/doc/donut.txt)。在文件中,添加一下内容:
*chocodonut* Delicious chocolate donut
*plaindonut* No choco goodness but still delicious nonetheless
如果您试着搜索 chocodonut 或 plaindonut (:h chocodonut 或 :h plaindonut),您找不到任何东西。
首先,你需要运行 :helptags来创建新的帮助入口。运行 :helptags ~/.vim/doc/
现在,如果您运行 :h chocodonut 或 :h plaindonut,您将找到上面那些新的帮助入口。注意,现在文件是只读的,而且类型是 “help”。
延时加载脚本
到现在,本章您学到的所有runtime路径都是自动运行的。如果您想手动加载一个脚本,可使用 autoload runtime路径。
创建一个目录名为 autoload(~/.vim/autoload/)。在目录中,创建一个新文件,起名为 tasty.vim (~/.vim/autoload/tasty.vim)。在文件中:
echo "tasty.vim global"
function tasty#donut()
echo "tasty#donut"
endfunction
注意,函数名是 tasty#donut 而不是 donut()。要想使用autoload功能,井号(#)是必须的。在使用autoload功能时,函数的命名惯例是:
function fileName#functionName()
...
endfunction
在本例中,文件名是 tasty.vim,而函数名是donut。
要调用一个函数,可以使用 call 命令。让我们call这个函数 :call tasty#donut()。
您第一次调用这个函数时,您应当会 同时 看到两条信息 (“tasty.vim global” 和 “tasty#donut”) 。后面再调用 tasty#donut 函数,将只会显示 “testy#donut”。
当您在Vim中打开一个文件,不像前面说的runtime路径,autoload脚本不会被自动加载。仅当您显式地调用 tasty#donut(),Vim才会查找文件tasty.vim,然后加载文件中的内容,包括函数 tasty#donut()。有些函数会占用大量资源,但我们又不常用,这时候 Autoload runtime路径就是最佳的解决方案。
您可以在autoload目录任意添加嵌套的目录。如果您有一个runtime路径 ~/.vim/autoload/one/two/three/tasty.vim,您可以使用:call one#two#three#tasty#donut()来调用函数。
After脚本
Vim有一个 after runtime路径 (~/.vim/after/) ,它的结构是 ~/.vim/的镜像。在此目录中的任何脚本都会最后执行,所以开发者通常使用这个路径来重载脚本。
比如,如果您想重载 plugin/chocolate.vim 中的脚本,您可以创建~/.vim/after/plugin/chocolate.vim来放置重载脚本。Vim将会先运行 ~/.vim/plugin/chocolate.vim, 然后运行 ~/.vim/after/plugin/chocolate.vim
$VIMRUNTIME
Vim有一个环境变量 $VIMRUNTIME 用来加载默认脚本和支持文件。您可以运行 :e $VIMRUNTIME查看。
它的结构应该看起来很熟悉。它包含的很多runtime路径都是我们本章前面学过的。
回想第22章,当您打开Vim时,它会在6个不同的位置查找vimrc文件。当时我说最后一个位置就是 $VIMRUNTIME/default.vim,如果Vim在前5个位置查找用户vimrc文件失败,就会使用default.vim 作为vimrc。
不知您是否尝试过,运行Vim是不加载比如vim-polyglot之类的语法插件,但您的文件依然有语法高亮?这是因为当Vim在runtime路径查找语法文件失败时,会从$VIMRUNTIME 的语法目录中查找语法文件。
查阅 :h $VIMRUNTIME了解更多信息。
Runtimepath选项
运行 :set runtimepath?,可以查看您的runtime路径。
如果您使用 Vim-Plug 或其他流行的第三方插件管理器,它应该会显示一个目录列表。比如,我的显示如下:
runtimepath=~/.vim,~/.vim/plugged/vim-signify,~/.vim/plugged/base16-vim,~/.vim/plugged/fzf.vim,~/.vim/plugged/fzf,~/.vim/plugged/vim-gutentags,~/.vim/plugged/tcomment_vim,~/.vim/plugged/emmet-vim,~/.vim/plugged/vim-fugitive,~/.vim/plugged/vim-sensible,~/.vim/plugged/lightline.vim, ...
插件管理器做了一件事,就是将每个插件添加到runtime路径中。每个runtime路径都有一个类似 ~/.vim/的目录结构。
如果您有一个目录 ~/box/of/donuts/,然后您想将这个目录添加到您的runtime路径中,您可以在vimrc中添加以下内容:
set rtp+=$HOME/box/of/donuts/
如果在 ~/box/of/donuts/ 里面,您有一个plugin目录 (~/box/of/donuts/plugin/hello.vim) 以及ftplugin目录 (~/box/of/donuts/ftplugin/chocodonut.vim),当您打开Vim时,Vim将会运行 plugin/hello.vim 中所有脚本。同样,当您打开一个 chocodonut 文件时,Vim 将会运行 ftplugin/chocodonut.vim。
自己试着做一下:创建一个任意目录,然后将它添加到您的 runtimepath中。添加一些我们本章学到的runtime路径。确保它们按预期工作。
聪明地学习Runtime
花点时间阅读本章,还有认真研究一下这些runtime路径。看一下真实环境下runtime路径是如何使用的。浏览一下您最喜欢的Vim插件仓库,仔细研究一下它的目录结构,您应该能够理解它们中的绝大部分。试着领会重点并跟着做。现在您已经理解了Vim的目录结构,您可以准备学习Vimscript了。