前言
并发(concurrency)vs 并行(parallellism)
- 并发是指两个或多个事件在同一时间间隔发生;而并行是指两个或者多个事件在同一时刻发生。
- 并发是在同一实体上的多个事件,并行是在不同实体上的多个事件。
CPU,内存与 磁盘 IO
在计算机系统中 CPU,内存与 磁盘 IO 三者完成任务的速度相差很大,CPU > 内存 > IO,那怎样平衡三者,提升整体速度呢?
- CPU 增加缓存,还不止一层缓存,平衡内存的慢
- CPU 能者多劳,通过分时复用,平衡 IO 的速度差异
- 优化编译指令
上面的方式缓解了木桶短板问题,但同时这种解决方案也伴随着产生新的原子性,可见性,和有序性的问题。
原子性
原子(atom)指化学反应不可再分的基本微粒,所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch。
一个简单的例子,假设有整形成员变量 count=0,现在两个线程同时对其进行 1000 次自增 count++,最后能得到 2000 吗?
当然不能,count++ 转换成 CPU 指令需要三步:先读取 count 的值,然后将值加 1,再将计算结果写入 count。所以不是一个原子操作,我们不能用高级语言思维来理解 CPU 的处理方式。
如果线程 A 在没有将计算结果写入 count 时,发生了线程上下文切换,切换到线程 B 执行,那么这一轮两个线程的自增操作最终导致 count 只会加 1(期望的是各自加 1,总共加 2)。
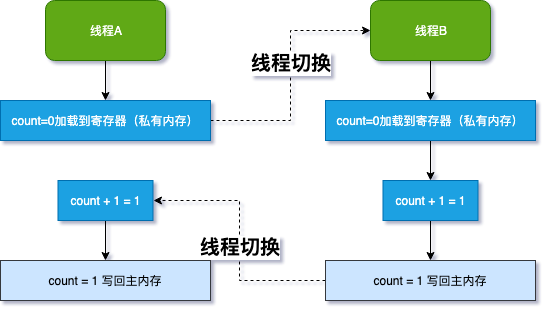
如何保证多个操作的原子性呢?最粗暴的方式是对自增方法加上 synchronized 关键字,但是 synchronized 是独占锁 (同一时间只能有一个线程可以调用),没有获取锁的线程会被阻塞;另外也会带来很多线程切换的上下文开销
所以 JDK 中就有了非阻塞 CAS (Compare and Swap) 算法实现的原子操作类 atomic 包,这是 JDK 的 rt.jar 包中的 Unsafe 类提供了硬件级别的原子性操作,类中的方法都是 native 修饰的。
可见性
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性。
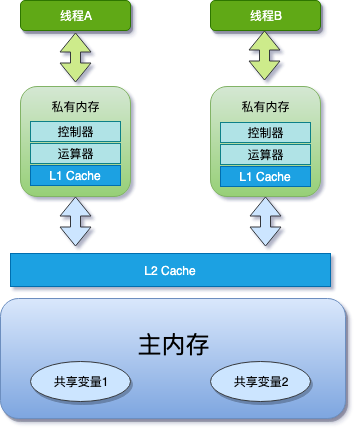
谈到可见性,要先引出 JMM (Java Memory Model) 概念, 即 Java 内存模型,Java 内存模型规定,将所有的变量都存放在主内存 中,当线程使用变量时,会把主内存里面的变量复制到自己的工作空间或者叫作私有内存 ,线程读写变量时操作的是自己工作内存中的变量,而刷回主内存的时间是不固定的。
为了平衡内存/IO 短板,会在 CPU 上增加缓存,每个核都只有自己的一级缓存,甚至有一个所有 CPU 都共享的二级缓存:
Note
在 Java 中,所有的实例域、静态域和数组元素都存储在堆内存中,堆内存在线程之间共享,暂且都称之为共享变量,局部变量,方法定义参数和异常处理器参数不会在线程之间共享,所以他们不会有内存可见性的问题,也就不受内存模型的影响。
要想解决多线程可见性问题,所有线程都必须要刷取主内存中的变量,可以使用 Java 关键字 volatile。
有序性
a = 1;
b = 2;
System.out.println(a);
System.out.println(b);
编译器优化后可能就变成这样的逻辑:
b = 2;
a = 1;
System.out.println(a);
System.out.println(b);
这个情况,编译器调整了语句顺序没什么影响,但编译器擅自优化顺序,就给我们埋下了雷,比如应用双重校验锁实现的单例:
public class Singleton {
private static Singleton instance; // 未使用 volatile 修饰
private Singleton (){}
public static Singleton getInstance() {
if(instance == null) {
synchronized(Singleton.class) {
if(instance == null){
instance = new Singleton();
}
}
}
return instance;
}
}
这是不正确的双重校验锁单例,问题出在 instance = new Singleton(),这一行代码转换成了 CPU 指令后又变成了 3 个,我们理解 new 对象应该是这样的:
- 分配一块内存 M
- 在内存 M 上初始化 Singleton 对象
- 然后 M 的地址赋值给 instance 变量
但编译器擅自优化后可能就变成了这样:
- 分配一块内存 M
- 然后将 M 的地址赋值给 instance 变量
- 在内存 M 上初始化 Singleton 对象
new 对象分了三步,给 CPU 留下了切换线程的机会;编译器优化后的顺序可能导致问题的发生:
- 线程 A 先执行 getInstance 方法,当执行到指令 2 时,恰好发生了线程切换
- 线程 B 刚进入到 getInstance 方法,判断 if 语句 instance 是否为空
- 线程 A 已经将 M 的地址赋值给了 instance 变量,所以线程 B 认为 instance 不为空
- 线程 B 直接 return instance 变量
- CPU 切换回线程 A,线程 A 完成后续初始化内容
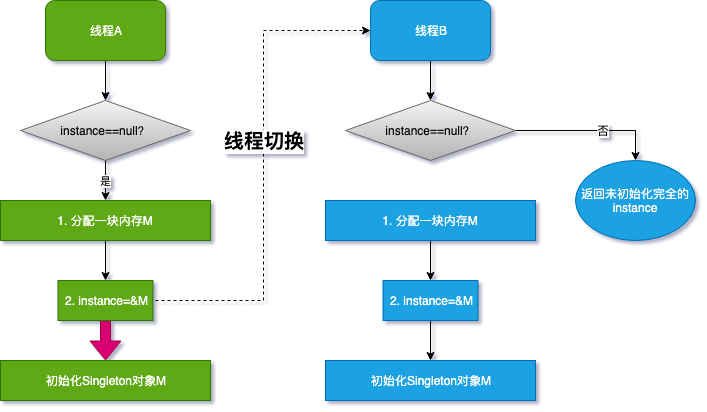
如果线程 A 执行到第 2 步,线程切换,由于线程 A 没有把红色箭头执行完全,线程 B 就会得到一个未初始化完全的对象,访问 instance 成员变量的时候就可能发生 NPE,如果将变量 instance 用 volatile 或者 final 修饰,问题就解决了。
synchronized
synchronized 两个缺点:
- 重量级锁
- 独占锁
参考 Java 锁
volatile
观察加入 volatile 关键字和没有加入 volatile 关键字时所生成的汇编代码发现,加入 volatile 关键字时,会多出一个 lock 前缀指令。
lock 前缀指令实际上相当于一个内存屏障(也成内存栅栏),提供 3 个功能:
- 它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
- 它会强制将对缓存的修改操作立即写入主存;
- 如果是写操作,它会导致其他 CPU 中对应的缓存行无效。
volatile 可以用来保障内存可见性(lock 前缀的第 2、3 功能)以及防止指令重排序(lock 前缀的功能 1),但不保证原子性。
内存可见性意思是:一个 CPU 核心对数据的修改,对其他 CPU 核心立即可见。
这句话拆开了理解,CPU 修改数据,首先是对缓存的修改,然后再同步回主存,在同步回主存的时候,如果其他 CPU 也缓存了这个数据,就会导致其他 CPU 缓存上的数据失效,这样,当其他 CPU 再去它的缓存读取这个数据的时候,发现自己缓存的数据无效,就必须从主存重新获取。
实现的原理一般都是基于 CPU 的 MESI 协议,其中 E 表示独占 Exclusive,S 表示 Shared,M 表示 Modify,I 表示 Invalid,如果一个核心修改了数据,那么这个核心的数据状态就会更新成 M,同时其他核心上的数据状态更新成 I,这个是通过 CPU 多核之间的嗅探机制实现的。
volatile 为什么不能保证原子性?
因为 CPU 写缓存不会校验状态,只有读缓存才会校验状态。
假设有 volatile 修饰的变量 n=1,现在 CPU 核心 A、B 都对 n 执行 n++ 操作。A 先执行:读取缓存,修改缓存、写入主存同时使其他 CPU 缓存失效。这时候只要我们保证 B 读取缓存在 A 使 B 缓存失效之前,那么 B 读取到的 n 依然等于 1,执行 n++ 操作之后写入主存结果还是为 2(尽管这时候 A 执行写入操作后主存 n 已经为 2)。所以,在多线程操作共享变量(例如:计数器)的时候,正确的方式是使用同步或者 Atomic 工具类。
指令重排序涉及到内存屏障(Memory Barrier),内存屏障有三种类型和一种伪类型:
- lfence:即读屏障(Load Barrier),在读指令前插入读屏障,可以让高速缓存中的数据失效,重新从主内存加载数据,以保证读取的是最新的数据。
- sfence:即写屏障(Store Barrier),在写指令之后插入写屏障,能让写入缓存的最新数据写回到主内存,以保证写入的数据立刻对其他线程可见。
- mfence,即全能屏障,具备 ifence 和 sfence 的能力。
- lock 前缀:lock 不是一种内存屏障,但它能完成类似全能型内存屏障的功能。
final
final 修饰类可以防止被继承,修饰方法可以防止被重写,修饰变量可以防止值被修改。
final 还有其他作用,通过 final 修饰变量来禁止 CPU 的指令重排,来提供线程的可见性,来保证对象的安全发布,防止对象引用被其它线程在对象被完全构造完成之前拿到并使用。
对于final域,编译器和处理器要遵守两个重排序规则:
- 在构造函数内对一个 final 域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
- 初次读一个包含 final 域的对象的引用,与随后初次读这个 final 域,这两个操作之间不能重排序。
与 volatile 有相似作用,不过 final 主要用于不可变变量(基本数据类型和非基本数据类型),进行安全的发布(初始化)。而 volatile可以用于安全的发布不可变变量,也可以提供可变变量的可见性。
CAS
CAS:Compare and Swap,比较并交换
ABA问题
CAS 需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是 A,变成了 B,又变成了 A,那么使用CAS 进行检查时会发现它的值没有发生变化,但是实际上却变化了。这就是 CAS 的 ABA 问题。 常见的解决思路是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么 A-B-A 就会变成 1A-2B-3A。 目前在 JDK 的 atomic 包里提供了一个类 AtomicStampedReference 来解决 ABA 问题。这个类的 compareAndSet 方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
自旋问题
自旋无非就是操作结果失败后继续循环操作,这种操作也称之为自旋锁,是一种乐观锁机制,一般来说都会给一个限定的自选次数,防止进入死循环。
自旋锁的优点是不需要休眠当前线程,因为自旋锁使用者一般保持锁时间非常短,因此选择自旋而不是休眠当前线程是提高并发性能的关键点,这是因为减少了很多不必要的线程上下文切换开销。
但是,如果 CAS 一直操作不成功,会造成长时间原地自旋,会给 CPU 带来非常大的执行开销。