前言
HashMap 是开发中存储数据经常用到的一个类,如无特殊提醒本文基于 java 7 源码介绍。
内部存储
HashMap 实现了接口 Map<K,V>,该接口的主要方法:
- V put(K key, V value)
- V get(Object key)
- V remove(Object key)
- Boolean containsKey(Object key)
HashMap 使用一个内部类来存储数据: Entry<K, V>,该类是一个简单的 key-value 键值对,同时包含两个额外数据:
- 指向下一个 Entry 的引用,使得 HashMap 能够把多个 Entry 像链表一样存储起来。
- key 的 hash 值,该 hash 值会经常使用,存储起来避免多次计算。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
···
}
HashMap 存储数据的是一个数组,数组的每一个元素是一条链表(也叫做桶或者箱),链表的节点就是 Entry。
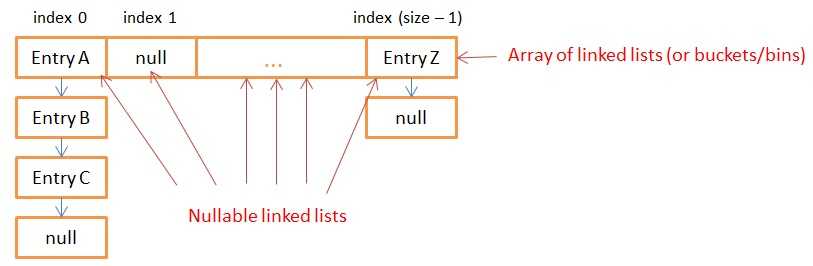
数组的初始长度为 16,所有具有相同 hash 值的 key 都放在同一链表(桶/箱)。
当调用 put(K key, V value) 或者 get(Object key) 时,函数会计算出 Entry 应该进入的桶的 index,然后遍历整个链表寻找相同 key 的 Entry(使用 key 的 equals() 方法)。 调用 get(),方法返回相应 Entry 的 value(前提是存在 key 相同的 Entry)。 调用 put(),如果 Entry 存在则更新 Entry 的 value 值,否则创建一个新的 Entry 并置于链表的表头。
生成桶的 index 包含 3 步:
- 获取 key 的 hashcode
- 二次 hash,防止一个比较差的 hash 函数把所有数据都分在了同一个桶。
- 将二次 hash 后的 hash 值与数组长度(减1)进行位掩码(与运算),该操作保证 index 不会超出数组的 size。
// the "rehash" function in JAVA 7 that takes the hashcode of the key
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// the "rehash" function in JAVA 8 that directly takes the key
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// the function that returns the index from the rehashed hash
static int indexFor(int h, int length) {
return h & (length-1);
}
为了使 index 能够均匀分布在数组里,数组的长度必须为 2 的幂次方即 2^n。
因为 2^n - 1 = 0x111···111(n 个 1),这样进行与运算后得到的 index 才能够保证分布均匀。
假设数组长度不是 2^n,比如长度 17,那么对于任何的 hash 值和 17 - 1 = 16 = 0x10000 进行与运算,index 结果要么为 16,要么为 0。所有的数据过于集中在部分桶,导致数组不够平衡,会对 HashMap 产生严重的效率影响。
自动扩容
基础概念
了解 HashMap 扩容前需要理解几个重要属性:
- capacity
- loadFactor
- threshold
- size
capacity 容量,指数组长度,也就是桶/箱的个数;loadFactor 负载因子;threshold 容量阈值;size 指 HashMap 存放的元素个数。
其中,threshold = capacity * loadFactor。
size 跟随 HashMap 存放的元素相应增减,当 size >= threshold 时,数组扩容、capacity 大小翻倍。
扩容原因
前面我们说了,HashMap 的存储结构是数组+链表,存放/获取元素分两步,第一步是获取通过 hash 值定位到数组的 index,第二步是遍历对应的链表查找是否存在相同 hash 值和 key 值的 Entry。
第一步的时间复杂度为 O(1),第二步的时间复杂度为 O(n)。扩容就是用空间换时间,增加数组的大小,减少链表的平均长度 n,使得 O(n) 变小。
初始容量
HashMap 的初始容量为 16,初始负载因子为 0.75。HashMap 有多个构造函数可供设置这些属性:
- public HashMap()
- public HashMap(int initialCapacity)
- public HashMap(int initialCapacity, float loadFactor)
根据应用场景选择一个合适的 initialCapacity 可以使得 HashMap 更高效。如果 initialCapacity 过小,使用过程中需要不断扩容,而扩容会对所有元素进行整体搬迁,开销较大。如果 initialCapacity 过大,则容易造成空间浪费。
容量强转
前面提及了如果数组长度不为 2^n 会导致数组元素分布不均匀, 那么如果设置一个大小合适的且不等于 2^n 的 initialCapacity 会有问题吗?
不必担心,HashMap 的设计者早已经考虑了这个问题,如果赋值的 initialCapacity 不等于 2^n,则会被强制转换成下一个最近的 2^n。转换的方法非常精妙,跟 LeetCode 1009 的解题思路很相似。
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
public static int highestOneBit(int i) {
// HD, Figure 3-1
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
Note: HashMap 只提供了扩容,并没有缩容。
key 不可变
为什么我们更倾向于使用字符串或者或者整数作为 HashMap 的 key?
因为字符串和整数不可变。使用自定义且可变的 Key class,可能会丢失存在 HashMap 内部的数据。
public class MutableKeyTest {
public static void main(String[] args) {
class MyKey {
Integer i;
public void setI(Integer i) {
this.i = i;
}
public MyKey(Integer i) {
this.i = i;
}
@Override
public int hashCode() {
return i;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof MyKey) {
return i.equals(((MyKey) obj).i);
} else
return false;
}
}
Map<MyKey, String> myMap = new HashMap<>();
MyKey key1 = new MyKey(1);
MyKey key2 = new MyKey(2);
myMap.put(key1, "test " + 1);
myMap.put(key2, "test " + 2);
// modifying key1
key1.setI(3);
String test1 = myMap.get(key1);
String test2 = myMap.get(key2);
System.out.println("test1= " + test1 + " test2=" + test2);
}
}
该测试输出结果为:test1= null test2=test 2
HashMap 在调用 get(key) 获取数据的时候,通过 equals() 方法比较 key 是否相等,测试代码中的 key1 修改属性之后不再满足 equals(),故查询不到结果,返回 null。
Java 8 改进
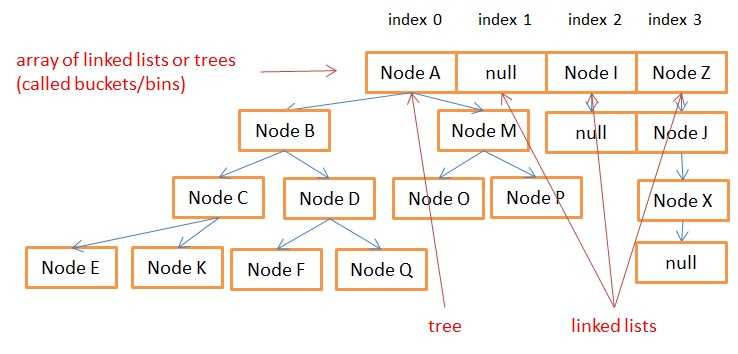
红黑树
桶加入了红黑树,不再是原来单一的链表结构。当链表元素大于等于 8 时,链表转换为红黑树;当红黑树结点小于等于 6 时,红黑树转换为链表。
红黑树使得在桶里查找的时间复杂度由链表的 O(n) 减小到 O(log(n))。
二次 hash
java 8 改进了二次 hash 函数,移除了 java 7 的 hashSeed。更有助于元素在数组内均匀分布或者执行效率更高?(没有实测,但总不至于越改越差吧)。
// the "rehash" function in JAVA 7 that takes the hashcode of the key
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// the "rehash" function in JAVA 8 that directly takes the key
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
capacity = 2^n
不同于 java 7 的 roundUpToPowerOf2(),java 8 重写了该方法且新命名为 tableSizeFor()。
java 7 先将 capacity 减 1,然后向左移一位,最后调用 Integer 类的取最高位方法(该方法先将 i 最高位右移填满所有低位,最后将 i 减去 i 右移一位后的值便是 i 的最高位)。
java 8 同样采用了移位的思想,但是进行了小优化,先将 capacity 减 1,然后直接最高位右移填满所有低位,最后再加一。
// JAVA 7
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
public static int highestOneBit(int i) {
// HD, Figure 3-1
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
// JAVA 8
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
假设 capacity = 23;2^4 < capacity < 2^5,所以转换后 capacity 的正确值应该为 2^5 = 32。
java 7:
- capacity = 23,二进制为 0x10111
- capacity 减 1,二进制为 0x10110
- capacity 左移一位,二进制为 0x101100
- capacity 最高位的 1 填满所有低位,二进制为 0x111111
- capacity 减去无符号右移一位后的值,即 0x111111 - 0x011111 = 0x100000 = 32
java 8:
- capacity = 23,二进制为 0x10111
- capacity 减 1,二进制为 0x10110
- capacity 最高位的 1 填满所有低位,二进制为 0x11111
- capacity 加 1,即 0x11111 + 0x1 = 0x100000 = 32
可以看到,java 8 的小优化理论上会更快一点点,前辈们追求完美的努力程度令我等汗颜😓。
Note
java 8 将 Entry 更名为 Node,大概是配合红黑树更顺口吧。
HashTable
线程安全
HashMap 不适合多线程使用,试想一个线程 put() 的时候触发了自动扩容机制,而这时另外一个线程来取数据则会找不到原来 Entry 所在的新桶。
HashTable 是线程安全的,因为所有的 CRUD 操作都被 synchronized 锁了起来,也正是如此 HashTable 效率会低很多。
若有多线程应用的场景,一个更好的办法是使用 ConcurrentHashMap。ConcurrentHashMap 采用分段锁,只要操作不是在同一个桶或者扩容就可以支持并发。
capacity
与 HashMap 2 的幂次方容量不同,HashTable 初始容量为 11,每次扩容容量翻倍且加 1。
容量不为 2^n 后,HashTable 使用取余操作来保证元素均匀分布在数组里。
int index = (hash & 0x7FFFFFFF) % tab.length;
总结
现在从头回顾下整个 HashMap 的设计:
存一堆数据最佳的数据结构是什么?
是数组,或者说线性表。这种数据结构在内存中分配的是一块连续的空间,可以通过首地址+偏移量(下标)的方式快速定位,时间复杂度为 O(1)。
Hash 是从一个无限元素集合到一个有限元素集合的映射,所以理论上一定会存在 hash 冲突,用 key 的 hash 值来确定数组下标也就意味着数组的每一个 item 都可能对应多个元素。于是出现了数组+链表的组合存储方式。
数组定位的时间复杂度 O(1),链表遍历的时间复杂度 O(n)。
在数组元素分布均衡的情况下,扩容可以降低链表的长度 n,从而减小时间复杂度 O(n),空间换时间。
二次 hash 保证元素在数组内分布更均匀,当然前提必须是一个足够好的 rehash 函数。
引入红黑树也是为了减小时间复杂度,从链表的 O(n) 降低到 O(log(n))。